[NLP] ELMo
ELMo
이번 포스팅에서는 Word Embedding 방법 중 하나인 ELMo에 대해 알아보도록 하겠습니다. ELMo가 등장하기 전엔 Word2Vec이나 GloVe 가 대표적인 Word Embedding 방법이었는데, NLP 분야가 점점 발전함에 따라 Context 를 더욱 잘 포함할 수 있는 임베딩 방식의 필요성이 높아지게 되었습니다. ELMo는 Bidirectional이라는 것을 활용하여 같은 단어라도 다른 뜻을 의미한다면 서로 다른 그에 맞는 적절한 Embedding 값을 가질 수 있도록 합니다. 그럼 이제부터 좀 더 자세히 살펴보도록 합시다.
Bidirectional Language Models (biLM)
ELMo에 대해 자세히 알아보려면 biLM 이라는 것을 알아야 합니다. biLM은 _Bidirectional Language Models_로, 명칭 그대로 양방향을 모두 살펴보는 모델을 의미합니다. Forward Language Model과 Backward Language Model을 나눠 알아봅시다.
-
Forward Language Model :
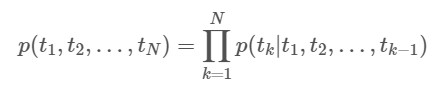
위 식과 명칭을 통해 알 수 있듯, Forward Language Model은 이전 tokens (t_1,….,t_k-1)가 주어졌을 때 그 다음 token t_k 가 나올 확률을 계산하는 모델입니다. 일반적으로 token 단위 임베딩을 먼저 수행해서 그 값을 LSTM의 layers에 전달하여 computation을 진행하고, 결론적으로 나오는 output과 Softmax layer를 활용하여 Next token prediction을 수행합니다.
-
Backward Language Model :
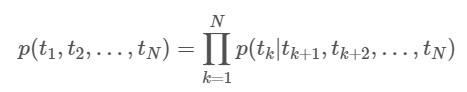
Backward Language Model은 그냥 Forward LM의 방향을 반대로 해준 것입니다. 즉, Forward LM은 이전 토큰들로 다음 토큰을 예측하는 모델, Backward LM은 다음 토큰들로 이전 토큰을 예측하는 모델이라고 볼 수 있겠습니다.
-
Bidirectional Language Model :
위 Forward와 Backward LM을 합친 biLM은 둘을 결합시킨 Likelihood를 최대화하는 방향으로 모델링됩니다.
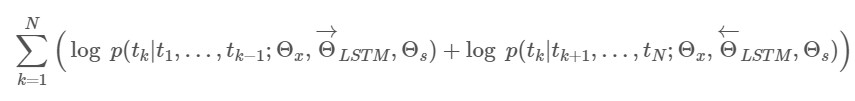
이를 간단하게 그림으로 나타내면 아래와 같습니다.

Details
위에서 biLM을 알아봄으로써 ELMo의 Main Idea에 대해서는 살펴보았습니다. 그렇다면 이번 Section에서는 좀 더 자세한 detail 몇 가지를 짚고 넘어갑시다.
- 뒷부분에서 좀 더 설명하겠지만 ELMo는 단순히 LSTM의 최종 layer만 갖다쓰는 것이 아니라, 각 은닉층 layer 결과들까지 가중합하여 최종값을 도출하는 형태입니다. 일반적으로 LSTM의 low-level layers는 문법 정보를, high-level layers는 문맥 정보를 학습하는 경향이 있다고 알려져있고, 이러한 정보를 모두 활용하는 ELMo의 성능은 자연스럽게 높아지게 됩니다.
- Input이 되는 Word Embedding 방법으로는 Char-CNN 이라는 방법을 사용한다고 합니다. Character-level 임베딩을 활용하는 이유는 Input Embedding은 문맥의 영향을 받지 않아야하기 때문이라고 합니다. 그리고 이렇게 Character-level로 계산하게 되면 OOV 에 비교적 robust 하다는 장점 등이 있습니다.
- LSTM layer 사이에 Residual connection을 사용합니다. 이렇게 하면 Gradient Vanishing 현상을 완화하고 high-level layer로 가도 low-level layer의 특성을 어느정도 유지하도록 해주는 등의 이점을 얻을 수 있습니다.
Procedure
앞서 언급했듯 ELMo는 Bidirectional 하게 계산한 후 각 layer의 출력값을 concatenate하고, 그것들을 가중합하여 최종 Representation을 산출합니다. 그 과정을 요약하면 아래와 같습니다.
(이 부분은 이곳 을 많이 참조하였습니다. 그림이 잘 나와있어서….)
-
1) 각 layer의 출력값 concatenate :

-
2) 각 layer의 출력값 별 weight 부여 :

-
3) Sum them up :

-
4) 벡터 크기 결정 :

이렇게 Weights나 기타 하이퍼 파라미터를 잘 설정하여 계산해주면 최종 ELMo 의 벡터 Representation이 산출됩니다.
+) 기존 Embedding vectors와의 결합
ELMo의 결과 벡터와 기존 모델 임베딩 벡터를 결합하여 NLP task를 수행하는 데 사용할 수 있다고 합니다. 방법은 그냥 Concatenate 하는 것입니다. 이렇게 결합하여 Target이 되는 NLP task를 잘 수행하도록 가중치나 파라미터를 훈련해주면 됩니다.

Evaluation
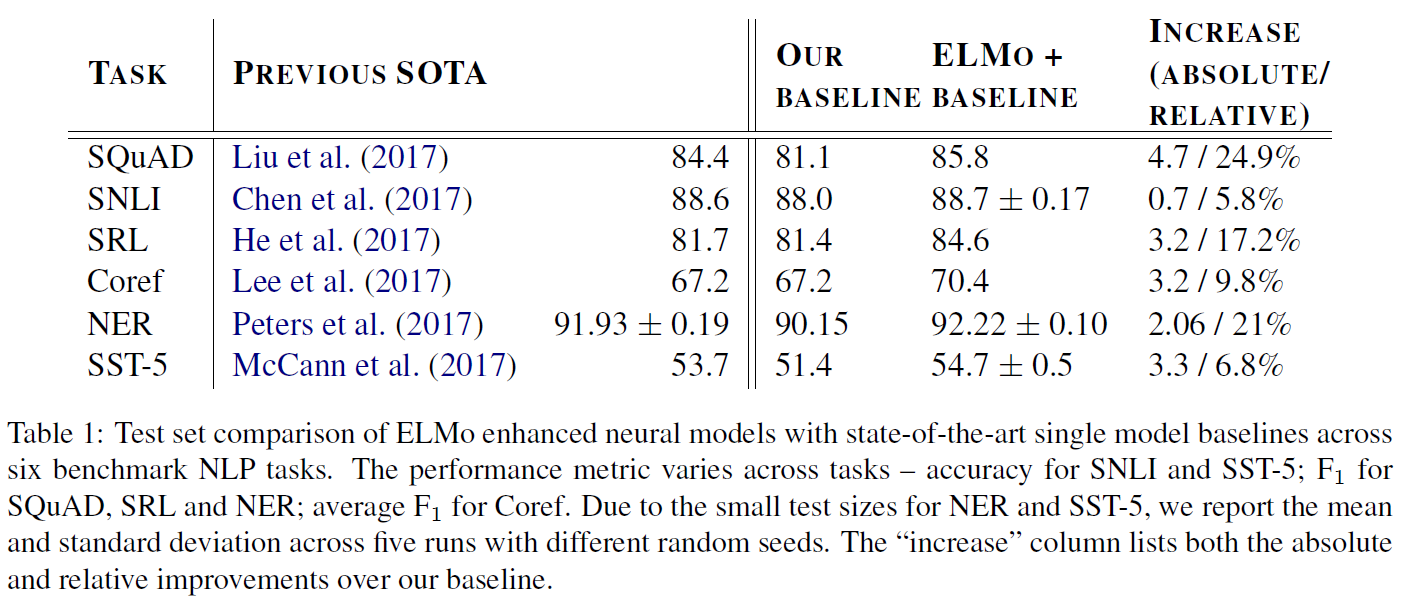
위 표를 보면 알 수 있듯, ELMo는 여러 NLP task에서 준수한 성능을 보여주었습니다.
이번 포스팅을 통해 Word Embedding 방법 중 하나인 ELMo에 대해 살펴보았습니다. 물론 ELMo representation이 모든 NLP task에 대해 잘 작동하는 것은 아니지만, 임베딩 방식에 있어서 여러 디테일을 고찰할 수 있도록 해주는 method인 것 같습니다!