[Paper Review] ERNIE: Enhanced Language Representation with Informative Entities
ERNIE
이번 포스팅에서는 ERNIE: Enhanced Language Representation with Informative Entities 논문 리뷰를 간단하게 해보도록 하겠습니다. ERNIE는 BERT 계 모델 중 하나로 BERT를 좀 더 발전시킨 버전이라고 보시면 되겠습니다. 그렇다면 이제부터 좀 더 자세히 살펴보도록 합시다.
Architecture
ERNIE는 요약하자면 다음과 같은 성질이 성립합니다.
- [Architecture] ERNIE = T-Encoder + K-Encoder
- [Concept] ERNIE = BERT + Knowledge Graphs
일단 Concept 부터 설명하자면 ERNIE는 BERT와 유사하나, Knowledge Graph를 활용하여 Entities에 대한 정보를 함께 고려해준다는 점에서 특징을 지닙니다. 이것이 Architecture 에 반영되어 Entities 관련 정보를 합쳐주는 K-Encoder가 추가되는 것입니다. T-Encoder는 BERT 내 기존 Transformer와 같습니다.
ERNIE의 전체적인 구조를 그림으로 표현하면 아래와 같습니다.
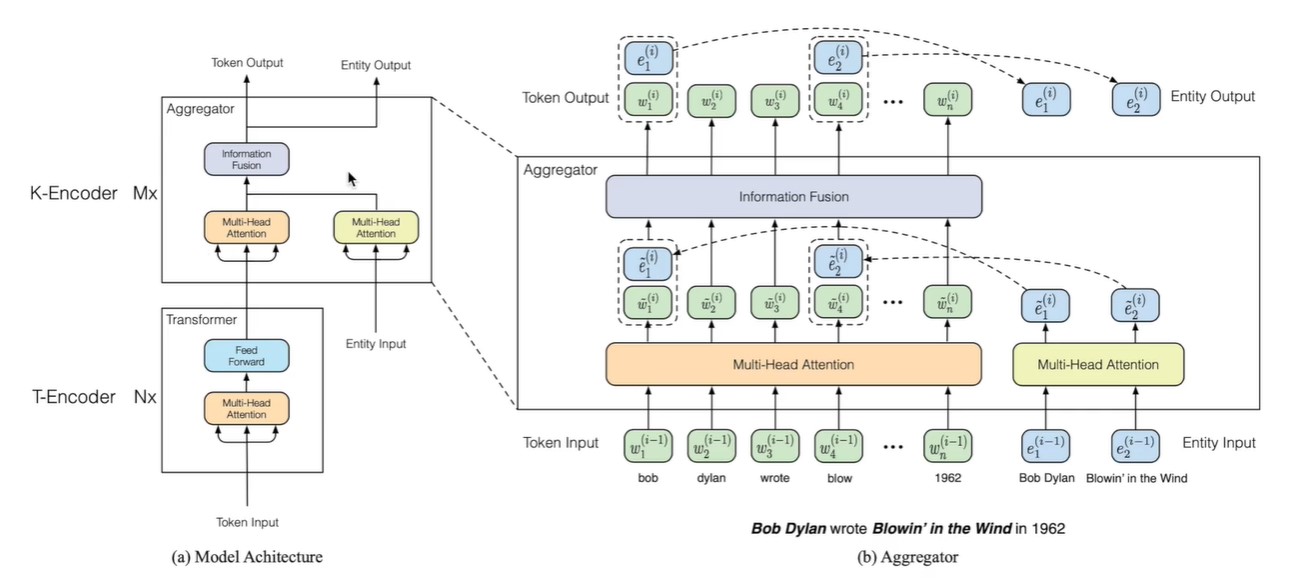
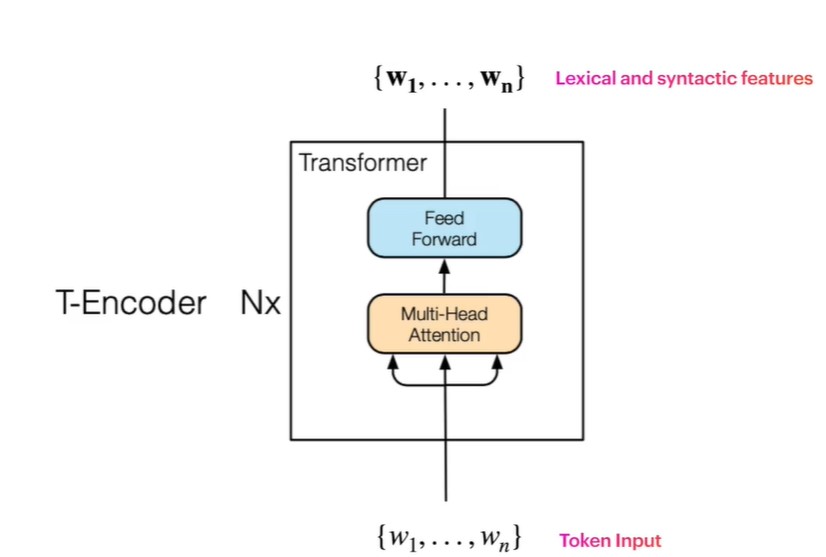
앞서 언급했듯 우선 T-Encoder는 Token input을 처리하는 Transformer 구조로, Text-Encoder를 의미합니다. Transformer에 대한 자세한 설명은 이전 BERT에 관한 포스팅을 참조하시길 바랍니다.
그리고 K-Encoder는 Token 과 Entity를 입력으로 받아 결합시키는 구조로, Entity Embedding에는 TransE와 같은 Knowledge graph 방식을 활용하여 이루어집니다.
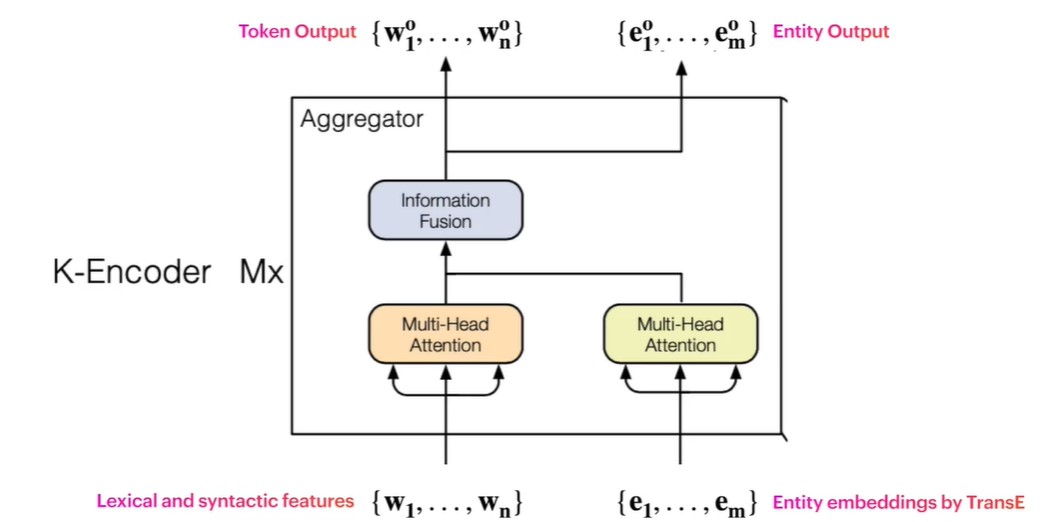
즉, Token을 통한 Lexical & Syntactic info와 Entity를 통한 Entity Embedding을 모두 받아 Information Fusion 을 진행하여 두 정보를 결합해주는 것입니다. Information Fusion 단계에서 각 정보를 어떻게 합치는지는 아래와 같습니다.

(+) 사실 T-Encoder만, 혹은 K-Encoder만 사용하지 않고 두 가지를 모두 거치는 이유는 아마 첫째, 성능이 더 좋아져서, 둘째, Token은 T-Encoder로 임베딩하고 Entity는 TransE로 따로 임베딩해서 각자 임베딩된 것들을 K-Encoder로 합쳐주기 위해서일 것이라고 추측해봅니다.
그렇다면 TransE란 무엇일까요? 간단하게 알아봅시다.
TransE

위와 같은 Knowledge Graph를 보면 우리는 Entity와 Relation이 다양한 타입으로 존재함을 알 수 있습니다. 이렇게 다양하게 존재하게 되면 Nodes가 같은 속성을 가져야하는 일반적인 Graph로 취급하기가 어려워져서, 이것을 잘 Embedding 할 수 있는 특수한 방법을 생각해내야하는데, 이것 중 하나가 바로 TransE 입니다.
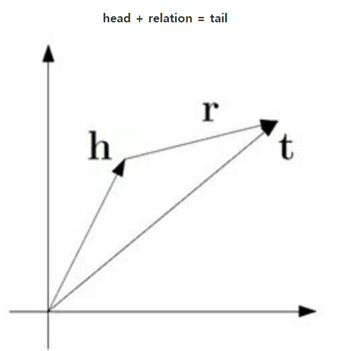
Direct Graph 에서는 그래프 구성요소로 Head(h), Relation(r), Tail(t)를 들 수 있습니다. 아래 그림에서 A가 Head, B가 Tail이며 화살표가 Relation에 해당되게 됩니다.

이 때, TransE는 Head와 Tail이 r이라는 Relation을 가지면 h+r=t를 만족한다고 봅니다. 그래서 적절한 임베딩을 위해서는 h+r-t를 모든 Entity & Relation에 대해 최소화시켜야 한다고 여기는 것이죠. 물론 개념은 이러하지만 이를 최대한 잘 적용시키기 위해선 여러 테크닉이 첨가되어야 하는데, TransE가 이번 포스팅의 목적은 아니므로 알고리즘 정도만 제시한 뒤 넘어가도록 하겠습니다.

Training ERNIE
일단 Training 단계에서 BERT와 유사하게 MLM과 NSP를 사용하는데, ERNIE에서는 여기에 denoising Entity AutoEncoder (dEA) 가 추가됩니다. dEA는 사실 우리가 기존에 아는 Denoising AutoEncoder와 유사한 개념인데 이것을 _Entity_를 기준으로 수행해준 것 뿐입니다. 즉, Entity에 대한 Noise를 훈련 과정 내 적절히 섞어주어 현실 데이터 적용 시 Error에 보다 Robust한 모델을 만들어주는 것입니다. 이를 위한 방법은 아래와 같습니다. (참고로 MLM과 NSP는 이전 BERT 포스팅 참조!)
- 1) 5% 정도의 Entity를 랜덤하게 다른 Entity로 교체
- 2) 15% 정도의 Token에 해당하는 Entity를 제거
- 3) 나머지 80% 정도는 변화 x
이렇게 적절히 섞어주게 되면 적용 데이터 내 잘못된 연결관계를 지닌 Token-Entity가 있는 등의 Error가 있어도 나름 괜찮은 결과를 내는 Error-robust한 모델을 형성할 수 있게 됩니다.
Evaluation
해당 ERNIE 논문에서는 Relation Classification, Entity Typing 등 여러 Task에 대한 실험을 진행하고 결과를 제시하였는데, 결과는 당연히 좋습니다 :)


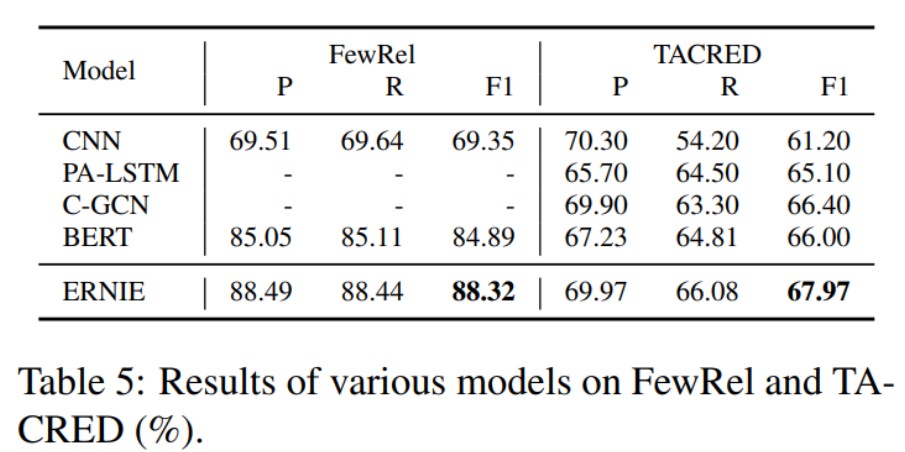
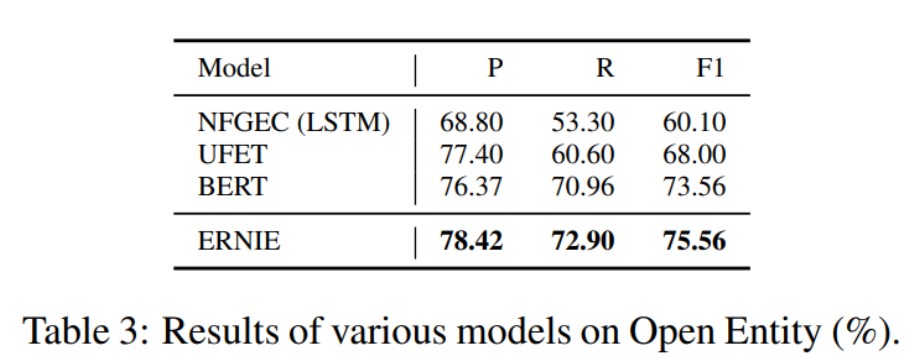
이번 포스팅에서는 BERT family 중 하나인 ERNIE에 대해 살펴보았습니다. 정말 BERT는 여러 방면에서 발전 가능성을 생각해볼만한 놀라운 모델인 것 같네요!