[Paper Review] RoBERTa: A Robustly Optimized BERT Pretraining Approach
RoBERTa
이번 포스팅에서는 이미 앞서 살펴보았던 유명한 “그” 모델, BERT를 좀 더 발전시킨 논문 “RoBERTa: A Robustly Optimized BERT Pretraining Approach” 에 대해 살펴보도록 하겠습니다. 간단하게 요약하자면 RoBERTa는 BERT의 여러 하이퍼 파라미터를 조정한 결과를 살펴보고, 그 외 Dynamic Masking을 도입해보는 등 다양한 실험을 해본 논문이라고 볼 수 있습니다. 그렇다면 이제부터 무엇이 주된 내용인지, 어떤 실험들이 수행되었는지 차근차근 알아보도록 합시다.
Key points
일단 RoBERTa는 BERT와 비교했을 때 크게 4가지의 차이가 존재합니다.
-
1) Larger Data size & Batch size
-
2) Longer Sequences
-
3) NSP (Next Sentence Prediction) 제거
-
4) Dynamic Masking
+) Different Text Encoding method
위와 같은 4가지 차이점을 기반으로 한 실험의 세팅 및 결과를 중심으로 전개해보도록 하겠습니다.
1) Larger Data & Batch Size
RoBERTa의 저자들은 BERT가 under-trained 되었다고 주장합니다. 즉, 이미 여러 분야에서 BERT를 활용하여 Fine-tune한 모델들이 좋은 성과를 낸 것임에는 분명하나, 좀 더 잘 Training 시킬 수 있는 방법이 존재할 것이라는 주장입니다. 그래서 저자들은 더 많은 데이터를 투입하고, BERT와 비슷한 세팅이지만 하이퍼 파라미터 등을 약간 조정하여 모델을 “다시” 구현합니다. RoBERTa에 사용된 데이터들은 아래와 같습니다.
- BookCorpus & English Wikipedia & Wekipedia : 16GB
- Common Crawl News corpus : 76GB
- Open Web Text : 38GB
- Stories : 31GB
이렇게 해서 BERT에서는 약 16GB 정도의 위키피디아 위주 데이터가 사용되었던 것에 반해, RoBERTa에서는 약 160GB 정도의 다양한 데이터가 사용되었습니다. 위에서 보다시피 크롤링 데이터가 많이 포함되면서 다소 dirty한 데이터도 활용되었음을 알 수 있습니다. 데이터 양과 관련된 실험의 결과는 다음과 같습니다.
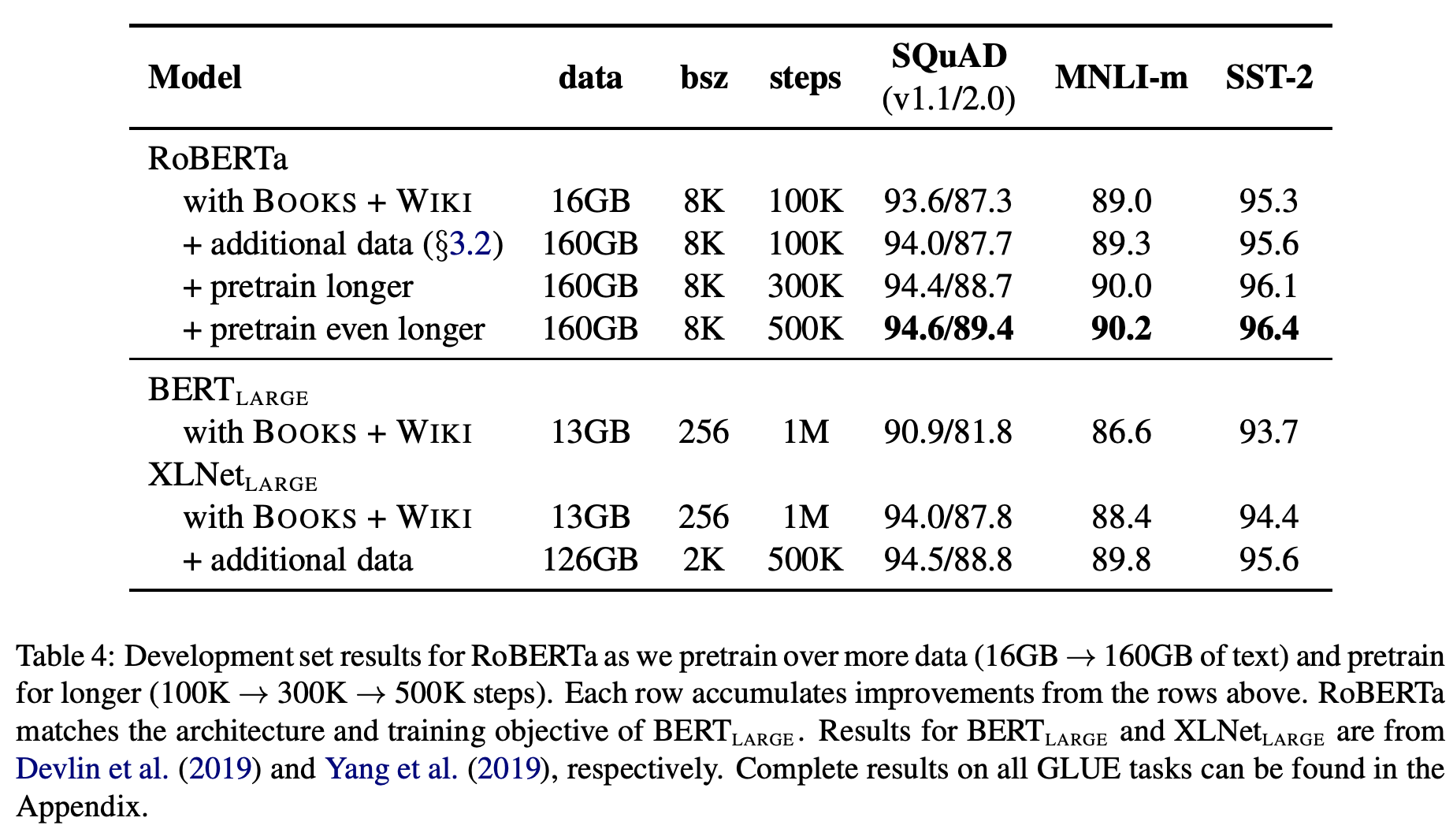
위 표를 보면 더 큰 데이터로 더 오래 (longer steps) 학습할수록 결과가 좋아짐을 확인할 수 있습니다. 저자들의 말에 따르면 데이터를 늘려가며 훈련하면 steps가 길어져도 overfitting이 나타나지 않았다고 합니다. 결과적으로 해당 논문에서는 BERT와 같은 pretrained models에서 데이터 양의 중요성을 강조하며 모델의 발전 가능성을 제시합니다.
데이터의 양 외에도 RoBERTa에서는 Batch size 등 주요 하이퍼 파라미터도 조정해주었습니다. 구체적인 세팅은 아래와 같습니다.
-
Batch Size : 2K ~ 8K 등 기존 BERT의 256 정도에서 대폭 증가
- Optimizer : Adam 사용 & Batch size가 커져도 잘 학습될 수 있도록 0.98 정도로 베타 조정
- Learning rate / Warm up step : Batch size에 맞게 튜닝
그 외 Sequence Length 등과 같은 세팅은 해당 파트를 설명할 때 더 언급하도록 하겠습니다. 우선 위처럼 Batch size 늘리고 그에 따라 lr이나 optimization parameter를 맞춰줌으로써 저자들은 아래처럼 더 나아진 결과를 얻어냅니다. 추가적으로 Batch size가 커지면 Parallelization 등에서도 이점을 얻을 수 있다고 합니다.
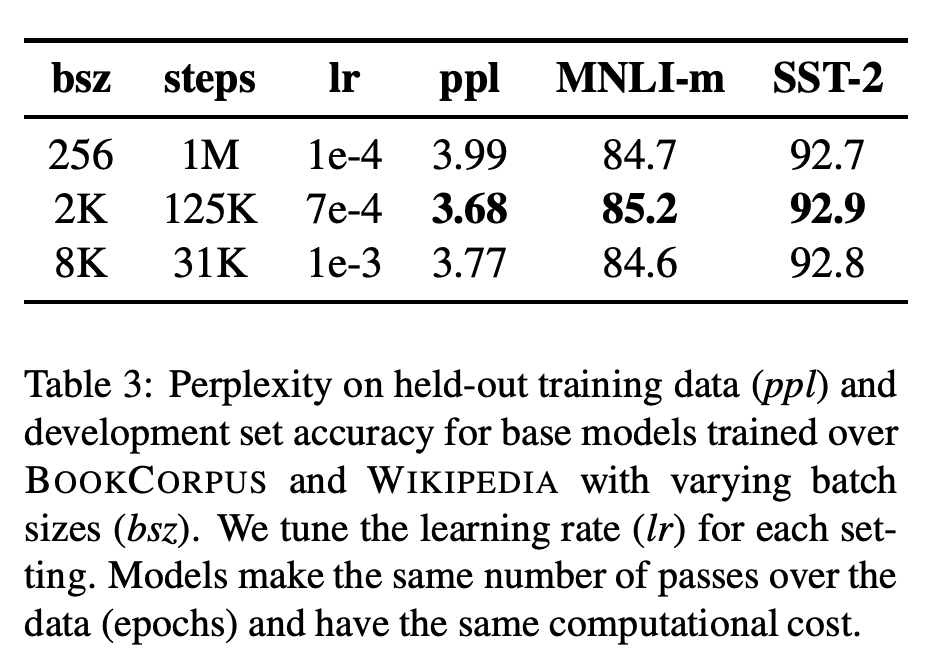
결론적으로 RoBERTa 에서는 Larger Data & Batch size 및 관련 하이퍼 파라미터 조정을 통해 기존 BERT보다 더 발전된 결과를 도출할 수 있음을 보여주었습니다.
2) Longer Sequences
Longer sequences를 사용했다는 것은 사실 _Larger Data & Batch size_와 비슷한 맥락입니다. BERT에서는 짧은 문장이 들어왔을 때도 좋은 결과를 내게 하기 위해 일정 확률로 랜덤하게 짧은 길이의 문장(NOT 512)을 input에 섞어 넣었습니다. 하지만 RoBERTa에서는 full length인 512 tokens를 채우도록 문장들을 최대한 이어붙여 input으로 사용하였습니다. 이렇게 했을 때 더 나은 결과물이 나왔다고 합니다.
3) NSP 제거
저자들은 NSP (Next Sentence Prediction)의 효과를 검증하기 위해 다음과 같은 4가지 input 구성으로 실험을 수행하였습니다.
- 1) Segment + NSP : 기존 BERT와 동일
- 2) Sentence + NSP : 각 Segment를 한 Sentence로 구성. 이렇게 하면 Segment가 짧아져서 Batch size의 조정이 요구됨(늘리기)
- 3) Full Sentence : 여러 문서들에서 연속적 샘플링을 통해 input을 구성. 하나의 문서가 끝나면 다른 문서를 바로 연결함으로써 Full length를 채우도록 함.
- 4) Doc Sentence : Full Sentence와 비슷하나, 여러 문서가 아닌 하나의 문서만 활용. 이렇게 하면 Full length를 못 채울 수 있는데, 그럴 경우엔 Batch size 조절을 통해 매번 optimize되는 token 개수 유지
이러한 세팅들로 실험을 수행한 결과는 아래와 같습니다.
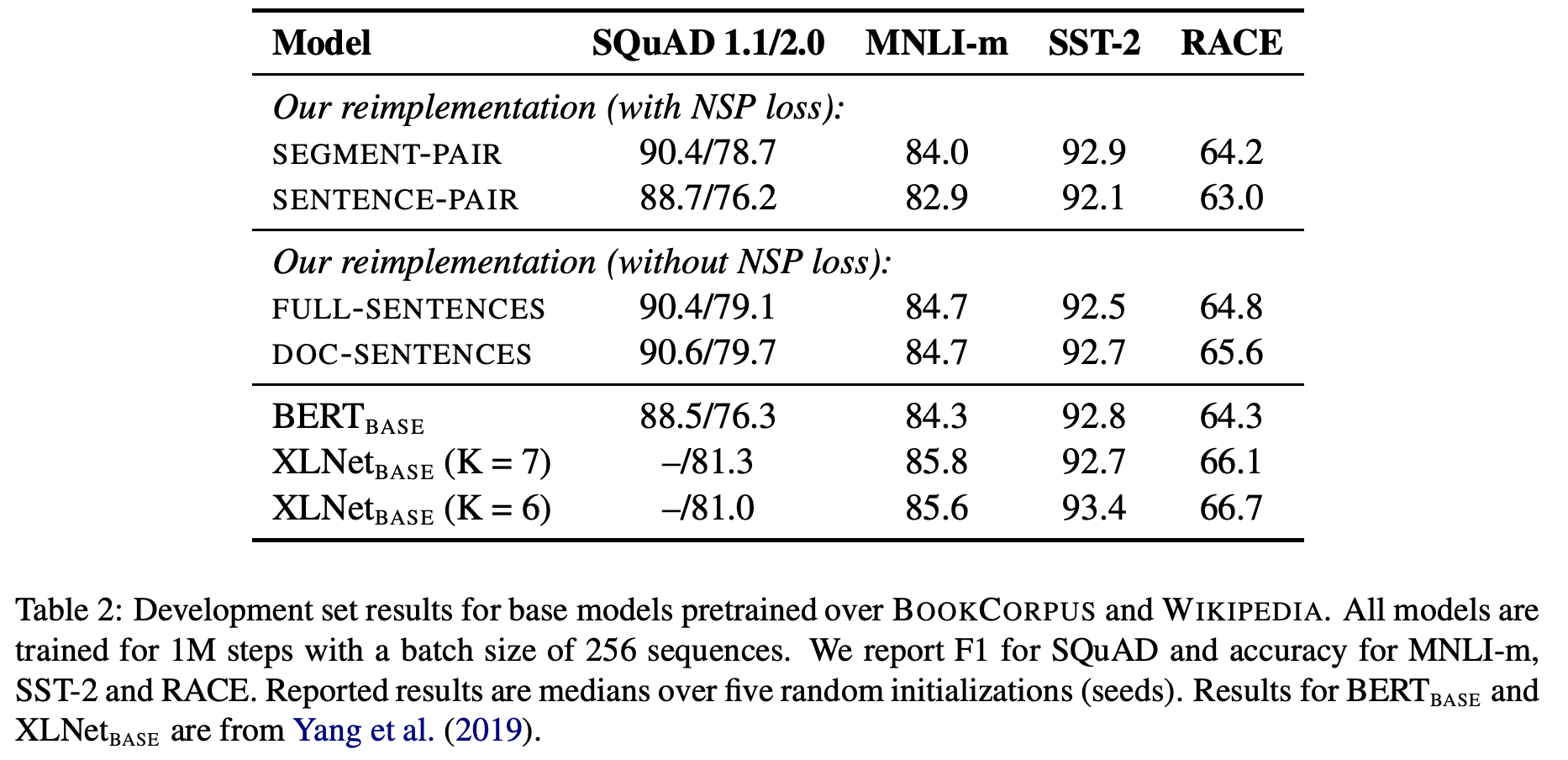
위 결과를 보면 알 수 있듯, NSP가 제거된 Full Sentence와 Doc Sentence가 더 나은 결과를 보입니다. 이는 모델을 훈련시키는 데 있어 NSP loss의 포함이 그리 critical 하지 않을 수 있다는 증거가 될 수 있습니다. 정량적인 수치만 보면 Doc Sentence가 아주 약간 더 낫지만, 이 경우엔 앞서 언급했듯 Batch size 조정이 요구되기 때문에 다른 실험 세팅에서는 그냥 Full Sentence를 사용했다고 합니다.
4) Dynamic Masking
BERT에서는 Static Masking, 즉 일정한 Masking pattern을 사용하여 훈련을 진행하였습니다. 이는 동일한 Masking을 갖는 input 문장들이 반복해서 등장한다는 것을 의미합니다. 저자들은 이러한 Static Masking 말고 매 epoch 마다 다른 Masking을 사용하는 Dynamic Masking을 적용하면 더 좋은 결과를 얻을 수 있지 않을까 고안하여 직접 실험을 수행하였습니다. 동일 환경에서 Static Masking & Dynamic Masking을 나눠 실험한 결과는 다음과 같습니다.
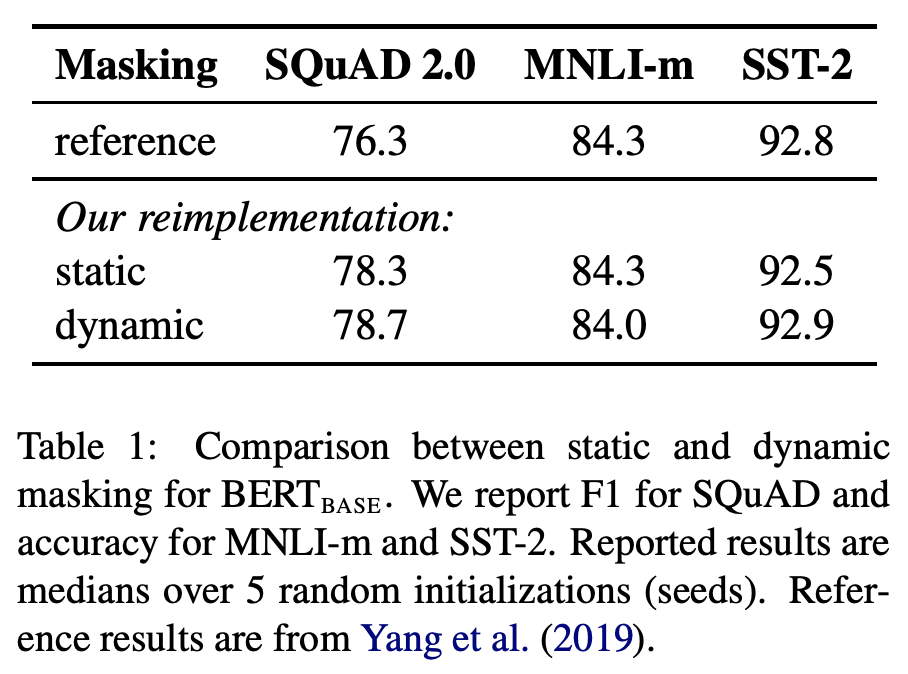
위 결과를 보면 Dynamic Masking의 결과가 기존의 Static Masking과 비슷하거나 더 나음을 알 수 있습니다. 추가적으로 Dynamic한 세팅 내에서는 메모리도 아낄 수 있다고 합니다. 따라서 모델 훈련에 있어 Masking을 어떠한 방식으로 할 것인지도 좋은 논의점이 될 수 있겠습니다.
+) Text Encoding : Byte-Pair Encoding (BPE)
일단 BPE가 어떤 것인지는 이전 포스팅을 참고해주세요. BERT에서는 Character-level BPE (Dictionary size=30k)를 활용하여 훈련을 진행하였는데, RoBERTa에서는 Byte-level BPE(Dictionary size=50k)를 사용하였습니다. 사실 성능의 측면에서 큰 도움이 되는 세팅 변화는 아닌데 universal encoding 등의 장점을 이용하기 위해 이러한 세팅을 활용하기로 한 것 같습니다.
Final GLUE Results
마지막으로 GLUE 및 기타 task에 적용한 결과를 정리한 것은 아래와 같습니다.
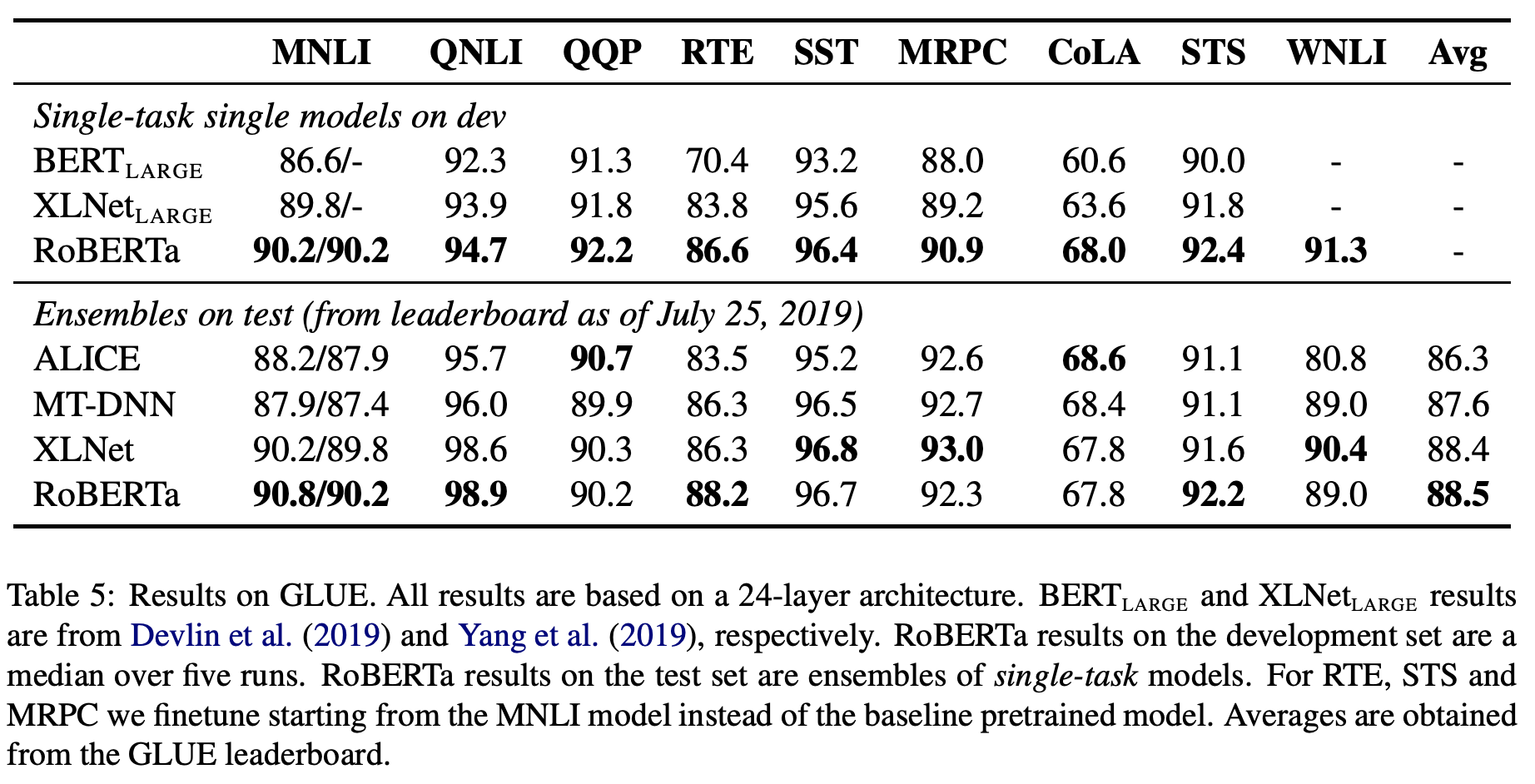
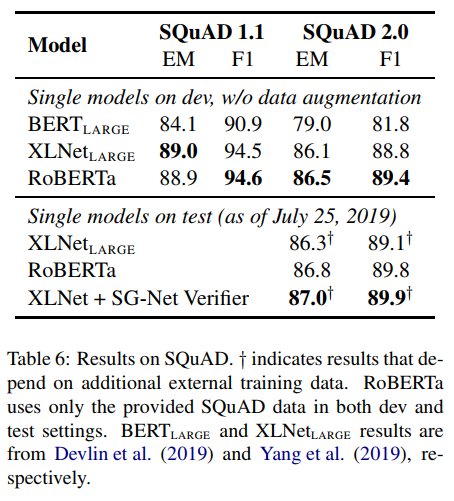
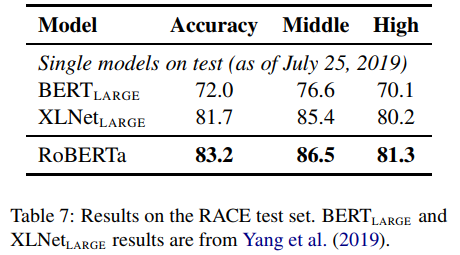
결론적으로 RoBERTa는 전반적으로 기존 모델들보다 더 나은 결과를 보이고 있습니다. 본 논문을 통해 우리는 하이퍼 파라미터 세팅, 데이터의 양, Masking 방법 등 다양한 요소들의 중요도가 생각보다 높을 수 있음을 알 수 있었습니다. 따라서 모델 개발 및 데이터 분석 시 모델 구조 등도 물론 중요하지만 이러한 세밀한 부분까지도 잘 고려할 수 있도록 해야겠습니다.