[NLP] AutoEncoder
AutoEncoder
Autoencoder는 딥러닝에서 많이 쓰이는 모델 중 하나로, input과 비슷한 output을 뱉어내는 구조를 지니고 있다. Encoder 파트와 Decoder 파트를 이용하여 이러한 역할을 수행하는데, 이번 포스팅에서 Autoencoder의 구조와 종류, 활용처 등을 간략히 살펴보도록 하자.
Architecture
Autoencoder는 아래 그림과 같은 구조를 가지고 있다.

위에서 볼 수 있듯, Encoder와 Decoder가 있는데 Encoder는 입력값 x를 latent representation z로 변환해주는 기능을 한다. NLP에서의 예를 들면 어떤 문장의 임베딩값을 input x로 넣었을 때, 그것의 핵심을 잘 표현해주는 representation z를 만들어주는 것이다. Decoder의 경우 Encoder에서 이렇게 만들어준 z를 이용하여 다시 x를 reconstruct한 x’으로 바꾸어주는 기능을 한다.
결국 이러한 구조를 거쳐서 나온 input x는 그와 유사하지만 완전히 identical하지는 않은 x’이 되어 산출된다. Autoencoder는 일단 label이나 정답이 따로 정해져있는 것이 아니기 때문에 Unsupervised learning이며, 좀 더 정확히는 Self-supervised learning이라고 볼 수 있다.
Related Model examples
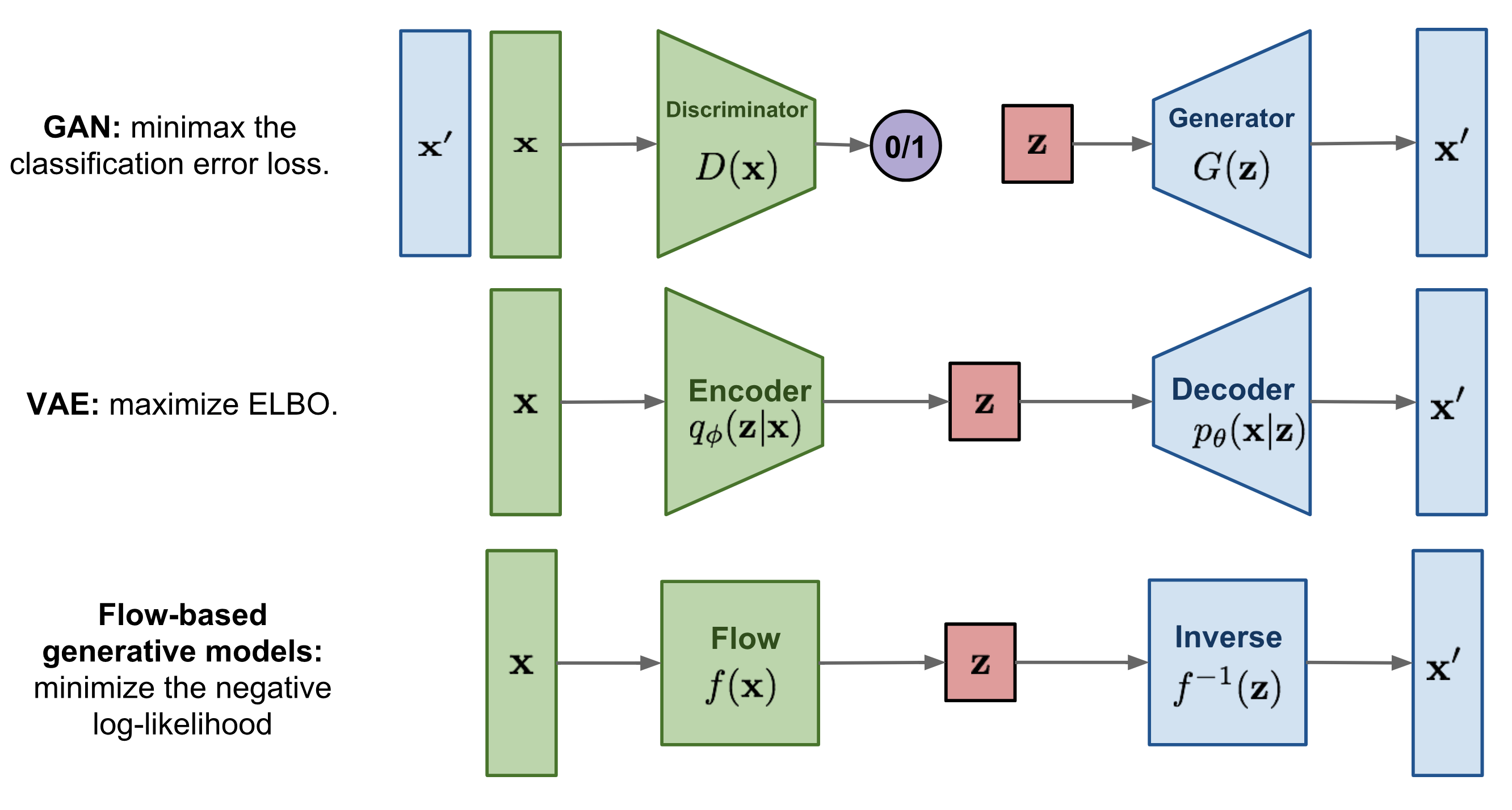
Autoencoder의 Decoder 부분은 결국 어떤 z를 가지고 x’을 다시 ‘생성’해내는 것이기 때문에 generative model이라고 볼 수 있다. Generative model에는 대표적으로 GAN, VAE 등이 있고 최근 이미지 생성 분야에서 조금씩 언급되는 Flow-based model도 있다.
GAN의 경우 fake를 generate 하는 부분과 그것을 진짜와 구별해내는 discriminator로 구성되어 있으며, 성능이 뛰어나지만 훈련의 안정성이 다소 떨어지고(convergence 보장이 어려움) mode collapse 문제 등의 단점이 존재한다. VAE의 경우 GAN보다 성능 자체는 조금 떨어져서 이미지 등을 generate하게 되면 blurry하다는 단점이 있지만 latent vector z를 확률과 결부하여 얻을 수 있게 해석력이 보완되고 훈련의 안정성이 좀 더 보장된다는 장점이 있다. 마지막으로 Flow-based model의 경우 간단히 표현하면(정확하지는 않을 수 있다) 어떤 invertible한 함수 f를 정해서 input x를 f(z)와 같은 식으로 transform (일종의 변수변환) 시키는 것이 Encoder 역할을 수행하고, 반대로 f의 역함수를 통해 다시 역변환을 해줌으로써 Decoder의 역할을 한다고 볼 수 있겠다. 다만 아직까지 Flow-based model의 경우 단독으로 사용하기에는 성능적 단점이 존재해 VAE나 GAN 등과 합쳐서 자주 사용되곤 한다.
Application & Keypoints
Autoencoder가 활용될 수 있는 분야는 다양하다. 입력데이터와 유사한 output을 나오게 하는 모델이기 때문에 입력데이터에 노이즈를 섞어서 넣은 뒤 output으로는 노이즈 없는 버전을 나오게 하는 Denoising 을 수행할 수도 있고, 특히 Encoder 파트는 input의 핵심을 압축해주는 역할을 하기 때문에 feature detection 등에 활용될 수도 있다. NLP에서는 Textual reconstruction 등에 활용될 수 있다고 보면 되겠다.
Autoencoder의 핵심은 input x 를 z로 잘 압축하는지와 원하는 목적대로 Loss function을 잘 만들었는지 정도를 꼽을 수 있겠다. Generation의 경우 원래 성능이 좋았던 GAN 위주로 사용하다가 Latent vector representation에 대한 중요성이 높아지면서 anomaly detection과 같은 분야에서는 기본 딥러닝 모델 + VAE 처럼 latent vector 생성에 집중을 하는 경향이 나타나는 것도 같다. 그리고 Loss function의 경우 TimeGAN처럼 Generator & Discriminator에 의해 산출되는 loss 외 Embedder-Recovery 부분을 첨가해서 두 구조에서 나오는 loss를 가중합 등 취해 훈련시키니 더 좋은 Time Series가 generate 되었다는 사례도 있다. 따라서 자신이 관심있는 분야가 어떤 flow로 Autoencoder / Generative model을 활용하고 있는지 잘 파악하는 것이 중요할 듯 하다.