[NLP] ELECTRA
ELECTRA
이번 포스팅에서는 구글이 BERT 이후로 또다시 발표한 Pre-trained model인 ELECTRA에 대해 살펴볼까 합니다. ELECTRA는 간단히 표현하면 BERT에서 효율성을 높인 버전이라고 보시면 되겠습니다. 언어 사전 훈련을 BERT와 약간 다르게 하여 더 적은 Computational cost로 BERT와 유사하거나 더 나은 결과를 낼 수 있다는 모델, ELECTRA에 대해 이제부터 자세히 살펴봅시다.
Main Idea
기존의 BERT와 같은 Pre-trained models는 여러 NLP tasks에서 좋은 결과를 내고 있습니다. 하지만 GPT나 BERT와 같은 모델들은 Current word 이전의 context만 사용한다든지 (ex) GPT), 양방향으로 본다고 해도 Masking으로 인해 Input의 Small portion만 학습시킬 수 있다는(ex) BERT <- MLM) 단점이 존재합니다. ELECTRA의 핵심 아이디어는 바로 이러한 훈련 과정 내 비효율성 을 줄이는 데에 있습니다. ELECTRA에서는 기존의 MLM 방식 대신 RTD (Replaced Token Detection) 이라는 새로운 언어 사전 훈련 방식을 채택하는데, 이를 통해 효율성과 성능 모두 잡을 수 있다고 합니다. 그렇다면 RTD 란 무엇일까요?
RTD (Replaced Token Detection)
RTD는 기존의 MLM 방식과 흐름 자체는 유사하나 [MASK] 토큰을 사용하지 않고 그것 대신 만들어진 가짜 토큰을 쓴다는 차이가 있습니다. 그리고 나서 “진짜”와 “가짜” 토큰을 구별하도록 모델을 훈련하는 것이죠. 이 방식을 수행하기 위해서는 가짜 토큰을 만들 Generator와 진짜와 가짜를 구별할Discriminator가 필요합니다. 따라서 ELECTRA에서 소개된 모델의 전체적인 구조는 아래와 같습니다.
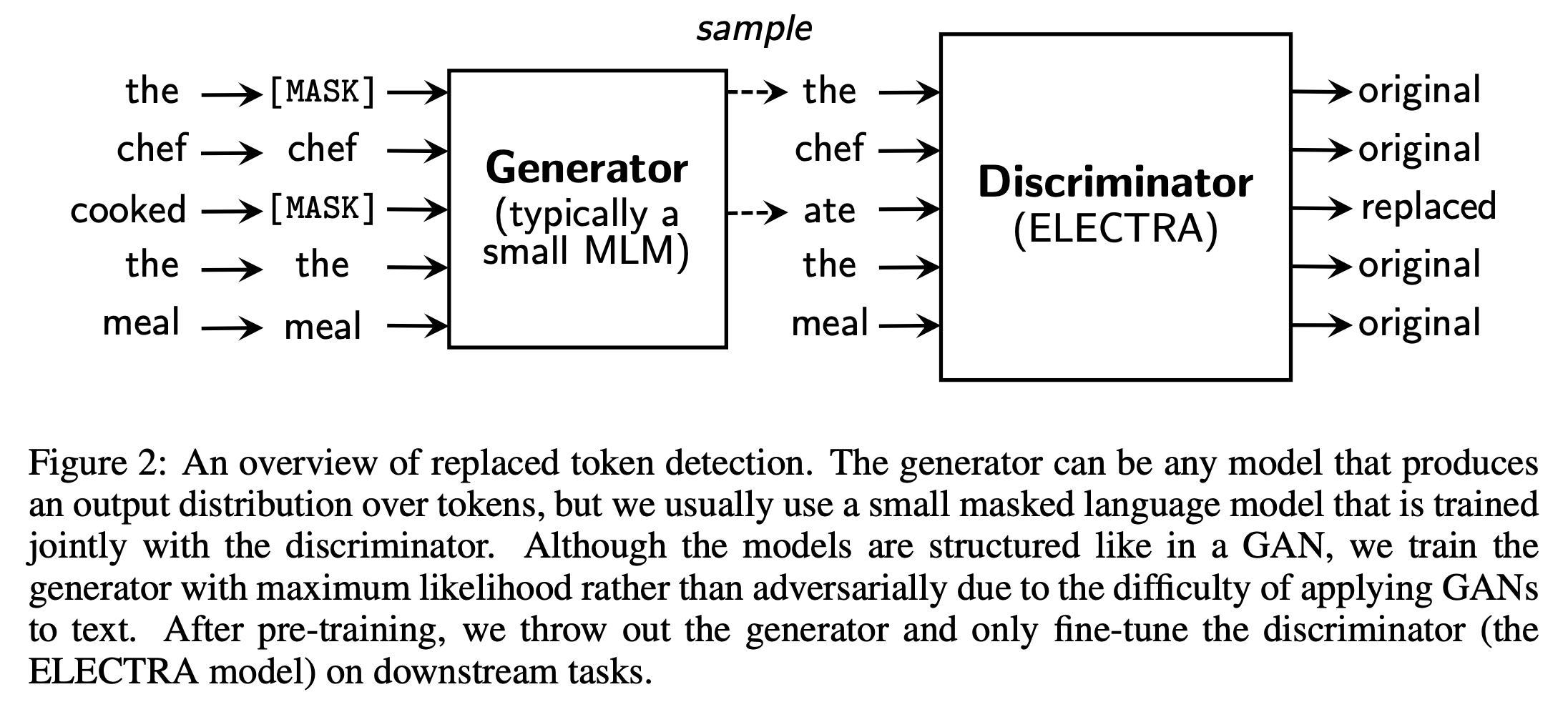
위 그림에서처럼 Generator에서는 가짜 토큰을 생성하고, Discriminator에서는 Original / Replaced 여부를 구별하는 방식으로 훈련이 진행되게 됩니다. 이렇게 훈련시키고 난 뒤 Fine-tuning을 할 때에는 Generator 파트는 버리고 Discriminator (ELECTRA model) 만 건져서 튜닝하여 Downstream tasks를 수행한다고 합니다.
Generator 부분은 결국 BERT의 MLM과 유사합니다. 일정 비율(주로 15%)의 토큰을 [MASK] 로 바꾼 뒤 이러한 입력들에 대해 원래 토큰이 무엇일지 예측하는 부분인 것이죠. Loss도 그냥 MLM loss를 그대로 사용합니다. 이렇게 Generator를 구성한 후, Discriminator에서는 Generator를 통해 형성된 input tokens에 대한 Softmax 분포에서 샘플링을 한 토큰을 [MASK] 대신 사용해줍니다. 위 그림처럼 원래 토큰이 “the”인데 샘플링된 토큰도 “the” 가 나올 수 있고, 반대로 원래 토큰은 “cooked” 인데 샘플링된 토큰은 “ate” 가 나올 수도 있습니다. Discriminator 는 결국 이러한 Original 여부를 잘 구별해낼 수 있는 방향으로 training이 됩니다.
Generator는 Small model로 구성하는 것이 좋다고 합니다. 사실 Generator와 Discriminator를 모두 BERT와 유사한 크기로 하게 되면 Computational cost가 보통의 MLM모델에 비해 2배가 되게 됩니다. 효율성을 높이기 위해서는 Generator의 크기를 줄이는 것 (layer의 크기 감소)이 좋고, 실제로 실험을 해봤을 때도 Generator는 Discriminator 대비 0.25~0.5 정도의 크기로 구성하는 것이 좋다고 합니다.
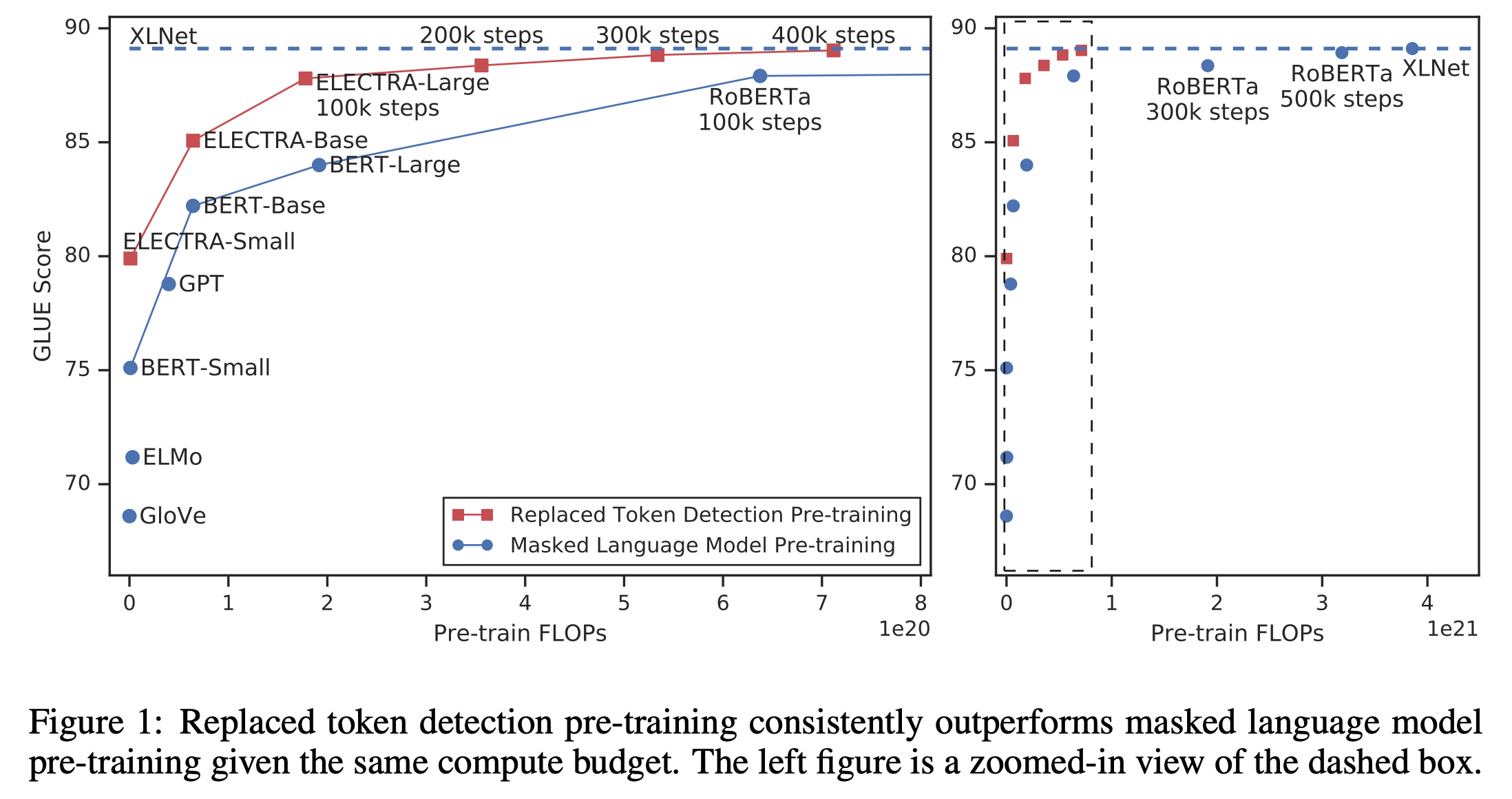
이처럼 모델을 구성하면 기존 MLM처럼 매번 15%정도의 토큰만 마스킹하여 이들에 대해서만 훈련할 필요없이, 모든 토큰을 대상으로 Discriminate 하는 식으로 훈련할 수 있게 되기 때문에, 보다 적은 example을 통해 동일한 성능을 달성할 수 있게 됩니다. 따라서 전체적인 Computational cost를 고려할 때 ELECTRA는 훨씬 적은 Cost로 기존 SOTA인 BERT나 RoBERTa, XLNet 등에 필적하는 결과를 낼 수 있다고 합니다.
(+) GAN과의 차이 ?
위에서 ELECTRA의 핵심에 대해서는 설명을 했습니다. 그런데 잘 살펴보면 결국 ELECTRA는 GAN과 유사한 것으로 보입니다. 둘의 차이에는 무엇이 있을까요? 차이점에는 크게 2가지를 꼽을 수 있습니다.
- 1) ELECTRA는 엄밀히 얘기해서 Adversarial하게 Generator를 학습하는 것은 아님. Maximum likelihood를 이용하여 훈련함. 샘플링이 들어가서 Backpropagation이 불가능하기 때문.
- 2) Generator 부분에서 Noise 벡터를 입력으로 활용하지 않음.
GAN과 비슷한 듯 다른 ELECTRA이기에 유의하시는 게 좋겠습니다.
일단 이번 포스팅에서는 ELECTRA라는 모델의 개념과 구조적 흐름에 대해 직관적으로 설명하는 것에 초점을 맞추었기 때문에 논문에서 다룬 구체적인 수식이나 훈련 디테일, 실험 결과(이건 물론 ELECTRA가 뛰어나다고 나옵니다..) 등에 대해서는 언급하지 않았습니다. Details를 알아보시고 싶다면 이 곳을 참조해주세요!