[NLP] Machine Reading Comprehension
Machine Reading Comprehension
이번 포스팅에서는 NLP에서 빠질 수 없는 Task 중 하나인 Machine Reading Comprehension (MRC) 에 대해 알아보겠습니다. MRC란 간단히 표현하면 ‘기계’ (Machine) 가 글을 ‘읽고’ (Reading) 스스로 질문에 알맞은 답안을 하는 등 ‘이해’ (Comprehension)를 잘 하도록 하는 task를 지칭한다고 할 수 있습니다. 이렇게 보면 꽤나 직관적인 task 명칭이라고 볼 수도 있겠죠?
그렇다면 MRC 를 수행하는 데 쓰이는 대표적인 데이터와 모델로는 어떤 것들이 쓰이는지 등을 자세히 살펴보도록 합시다.
Data
MRC 에서의 대표적인 데이터로는 SQuAD (Stanford Question Answering Dataset) 를 들 수 있습니다. 이 데이터는 Wikipedia article 셋에서 뽑아낸 질문과 reading passage에서 알아낼 수 있는 그에 상응하는 답변 pairs로 구성되어 있습니다. Version 1.1과 Version 2.0 등의 버전이 존재하며, Version 1.1에는 약 100k 이상의 question-answer pairs가 있고 Version 2.0 에는 answerable questions와 유사하게 보이도록 만들어진 50k 이상의 unanswerable questions가 기존 버전에 합쳐졌다고 합니다.
물론 SQuAD 데이터셋이 무조건 모든 방면에서 다 좋은 데이터는 아닙니다. Passages 내에서 정답을 찾는 구조라는 점과 문장 추론문제가 거의 없다는 점 등 단점이 분명 존재하나, 역시 오픈 데이터라는 장점과 비교적 clean 하다는 점에서 여전히 많이 쓰이고 있습니다. 연구를 시작할 때 접할 출발점으로 적합한 데이터이기 때문에 이 분야에서의 연구를 하실 분이라면 적어도 한번은 분석하게 되시지 않을까 싶습니다.
이 외 CNN / Daily Mail Dataset / Children’s Book Test 등의 데이터도 존재합니다. 참고로 Deep Learning Reader 모델을 구성해 이 데이터셋들을 분석한 논문은 이전 이전 포스팅 에서 찾아보실 수 있습니다.
Question Answering & Attentive Reader
Question Answering (QA) 태스크는 말 그대로 질문에 대한 답을 하는 태스크 입니다. 예를 들어 ‘미국의 대통령은 누구야?’ 라고 물었다면 ‘바이든 입니다.’ 등의 대답을 해내는 작업인 것이죠. 사실 이렇게만 보면 정보를 그냥 서치해서 알려주면 되니까 쉬운 태스크가 아니냐 라고 생각하실 수도 있습니다. 하지만 질문이 조금만 더 어려워진다면 이 태스크의 난이도도 급상승하게 됩니다.
예를 들어. ‘훈민정음이 궁극적으로 의미하는 것은 무엇이지?’ 라는 질문이 들어왔고, 이에 대한 답변을 기계 스스로 찾아내야 한다고 가정합시다. 사람이 이 질문을 본다면 ‘조선 최초의 우리말’ 등의 답변을 쉽게 내릴 수 있겠지만, 기계는 주어진 Passage의 문맥을 이해해서 해당 질문에 대한 답을 스스로 찾아내야 합니다. 생각보다 쉽지 않겠죠?
이러한 Task를 더 잘 수행하기 위해 나온 모델들에는 여러가지가 있는데, 이번 포스팅에서는 Attentive Reader 를 중심으로 설명해볼까 합니다.
-
Attentive Reader : Attentive Reader는 이름에서도 알 수 있듯, Attention을 활용합니다. Passage 내 주어진 문장들과 Query를 분석해서 핵심 내용/부분이 무엇인지 찾아내는 것이고, 이 과정에서 Attention이 쓰이게 되는 것입니다. 그리고 ‘문맥’ 을 파악하는 것이 중요한만큼, Bidirectional LSTM 과 같은 모델도 많이 사용하는 듯 합니다.

-
Standford Attentive Reader : 이 모델은 Standford에서 발표한 Attentive Reader 모델로, 큰 테크닉으로는 앞서 언급한 것처럼 Attention 과 Bidirectional LSTM을 사용합니다.
Attentive Reader를 쓰기 위해서는 일단 텍스트로 표현되어 있는 Question과 Passage 자체를 임베딩하여 벡터 형태로 만드는 과정이 필요합니다. Standford Attentive Reader에서는 Question 내 단어들을 GloVe로 임베딩한 후에 one-layer BiLSTM에 넣고 각 방향의 last hidden state를 이어서(concatenation) 질문 벡터 (Question vector)를 산출합니다. Passage vector의 경우도 Question vector와 유사한 과정을 거치지만 문장 내 단어 수만큼의 Passage vectors를 얻는다는 점에서 차이가 있습니다.
그렇다면 모델의 핵심인 Attention은 어떻게 활용되었을까요? 일단 편의상 Passage vector를 ‘p vector’, Question vector를 ‘q vector’ 라고 하겠습니다. 이 모델에서는 Attention을 이용하여 Start & End token을 예측하는데, 과정은 다음과 같습니다.
- 1) q vector와 k개의 p vector에 Attention을 적용하여 Softmax 취함
- 2) 앞서 구한 값들과 p vectors를 곱해서 sum 취함
- 3) 2)에서 구한 값에 linear transformation을 해서 argmax 하기
위처럼 하여 Start & End token을 구하면 되는 것입니다. 하지만 최근 Attention을 사용하는 것에 비해 확실히 좀 간단하다는 느낌이 들기는 합니다. 이것이 발표된 게 2016년쯤이니 지금과 같은 Attention research flow는 찾아보기 어려웠겠죠..? 어쨌든 이 모델을 그림으로 표현하면 아래와 같습니다.
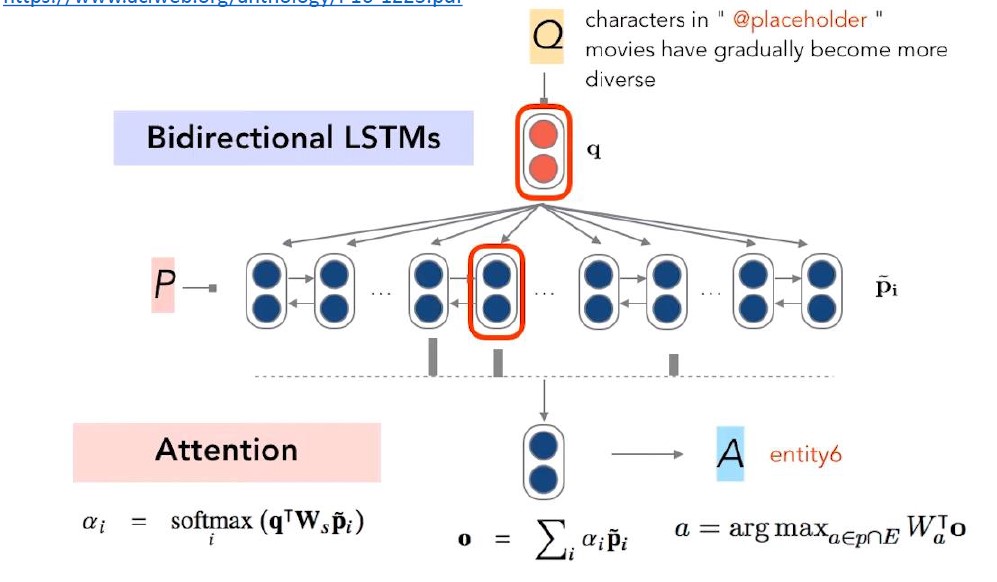
-
DeepMind Attentive Reader : 이 모델도 전체적인 framework은 위 Standford Attentive Reader와 유사하나 Attention 등과 관련된 식이 좀 다르다는 점이 차이입니다. 구조는 아래 그림과 같고, 이번 포스팅에서 디테일을 다루기에는 좀 무리가 있는 것 같아 일단 관련 리뷰 링크를 첨부해놓겠습니다.
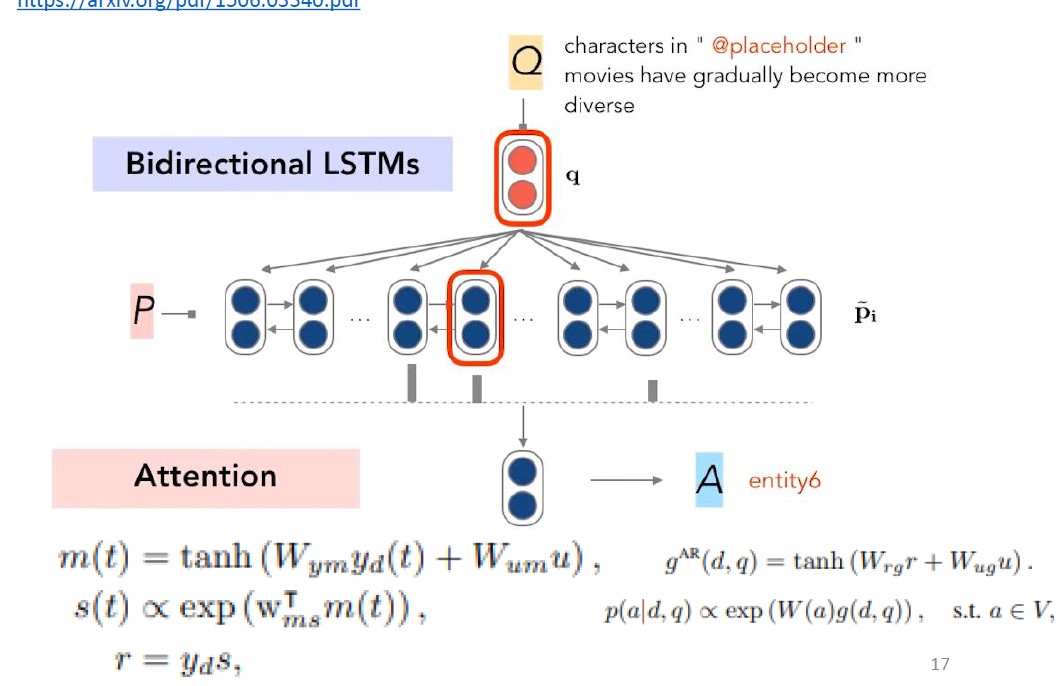
-
Standford Attentive Reader++ : 이 모델은 ‘++’ 가 붙은 것에서 추론할 수 있겠지만, 기존 Standford Attentive Reader에서 약간의 디테일이 바뀌었습니다. 바뀐 점을 정리하자면 다음과 같습니다.
- 1) 1 layer BiLSTM 에서 3 layer BiLSTM 으로 변화
- 2) q vector 생성 시 단순히 각 방향 last hidden state를 concat 하는 것이 아니라 position별 state를 concat 한 후 가중합으로 산출
- 3) p vector 생성 시 단어들의 GloVe 임베딩 값 외 Term frequency, linguistic features 등의 기타 정보들을 결합하여 산출
확실히 이렇게 모델을 좀 더 정교화하면 결과가 더 좋아질 수 있겠네요!
-
BiDAF : 이 모델의 경우 Standford Attentive Reader의 Attention 적용 양방향 버전 이라고 할 수 있겠습니다. 물론 디테일은 좀 차이가 있습니다만, 큰 틀을 보자면 그렇습니다. 핵심 디테일 및 순서는 다음과 같습니다.
- 1) charCNN 을 활용하여 character embedding
- 2) Pre-trained 임베딩 모델 사용하여 word embedding
- 3) 양방향 Attention 수행 : Query2Context & Context2Query -> 여기서 Context는 Standford Attentive Reader에서의 Passage라고 보시면 이해가 편하겠습니다. 즉, 이 모델에서는 q와 p 간 양방향 을 모두 살펴봄으로써 둘을 엮어 단순히 하나의 feature vector로 만드는 것이 아니라 문맥적으로 이어주는 특징이 있다고 할 수 있습니다.
- Context2Query : context와 query 단어 간 similarity (S)를 측정하여 여기에 Softmax 씌운 것을 attention weight으로 사용하여 Context 입장에서 유사한 Query의 특성 파악
- Query2Context : similarity matrix S에서 maxcol을 뽑아 Softmax 취한 뒤 이것을 context vector와 곱하여 더해줌으로써 Query 입장에서 중요한 Context word를 살림
- 4) 모델링 단계에서는 3)에서 구한 값들을 BiLSTM에 넣어 output을 뽑고 그것을 3) 결과값과 다시 concat 하여 linear transform & Softmax 취해 Start & End 토큰 예측
종합적인 과정을 그림으로 보자면 아래와 같습니다.

이번 포스팅을 통해 MRC 가 무엇인지, 그리고 분석을 위해 쓰이는 모델링에는 어떤 방식이 있는지 등을 살펴보았습니다. 이 분야에 대한 이해 및 연구 시작에 도움이 되셨으면 합니다~!