[NLP] MT-DNN
MT-DNN
이번 포스팅에서는 Multi-Task learning 이 무엇인지와 NLP에서의 활용 모델인 MT-DNN에 대해서 살펴보도록 하겠습니다.
Multi-Task learning
일단 Multi-task learning (MTL) 이란 관련 Tasks를 동시에 (simultaneously) 학습함으로써 모든 task의 overall performance를 향상시키고자 하는 학습 메커니즘입니다. 특히 single 모델을 사용하여 여러개의 Supervised tasks를 수행하고자 할 때 MTL을 많이 사용한다고 합니다. 쉽게 이야기하면, MTL은 ‘축구선수는 전문이 축구이더라도 일반인 보다는 농구를 더 잘할 것이다’ 와 같은 전제를 베이스로 한 학습 패러다임이라고 보시면 되겠습니다. 즉, task 측면에서 보자면 한 task를 수행할 때의 과정이 다른 유사한 task 수행 시 어떤 영향을 주어 performance에 도움을 줄 수 있다는 것이죠.
물론 MTL에 대한 장점과 단점이 존재합니다.
- 장점 :
- 1) 한정된 데이터를 보다 효율적으로 사용할 수 있음 : 어떤 Supervised task에 대한 dataset이 있는데 그 수가 적다거나 다른 문제가 있는 경우 MTL을 통해 그 영향을 완화할 수 있습니다. 여러 Task에 수행되는 Supervised data를 합쳐서 MTL을 수행하게 되면 performance가 나아질 수 있다는 것입니다.
- 2) 정규화(Regularizatoin) 효과 : 여러 task를 동시에 수행하기 때문에 한 task만 집중적으로 수행할 때 발생할 수 있는 overfitting을 완화해줍니다.
- 3) Computational efficiency : 여러 task를 동시에 수행하기에 당연한 장점이라고 할 수 있습니다.
- 단점 :
- 1) Negative Transfer : 어떤 task가 다른 task 수행 시 도움이 되는 게 아니라 오히려 방해가 될 가능성도 있습니다.
- 2) Task Balancing : 여러 Tasks 는 각기 다른 학습 난이도를 지니고 있는데, 이를 어떻게 조절하여 balancing 할 것인지에 대한 문제도 존재합니다.
그렇다면 MTL은 구체적으로 어떤 식으로 Task 간 정보를 공유해서 여러 Tasks를 동시에 수행하는 것일까요? Sharing methods 에는 크게 2가지가 있습니다.
-
Soft Sharing : 각자 다른 모델들에서 시작하여 중간중간에 information을 공유합니다.

-
Hard Sharing : 모두 같은 root 모델에서 출발하여 나중 가서 각자 learning 을 수행합니다.

자, 이제 Sharing methods까지 대충 감을 잡았습니다. 그럼 Loss 는 어떻게 잡는 것이 가장 효과적일까요? 사실 MTL에서 여러 Loss를 어떻게 합쳐서 효율적으로 학습할 것인가는 중요한 이슈입니다. Tasks가 어떤 것인지에 따라 달라지겠지만, 단순 모두 더해주는 것만이 능사는 아닐 수 있습니다. Task마다 loss scales 등이 달라질 수 있기 때문입니다.
Loss를 설정해주는 좋은 방법 중 하나는 task 별 uncertainty 에 따라 MTL 내 loss에 가중치를 부여하는 것입니다. 이것은 새로운 noise parameter를 따로 학습하여 loss에 결합해주면 됩니다. 더 자세한 절차는 이 곳을 참조해주세요!
MT-DNN
그렇다면 이제 NLP 분야에서 MTL을 적용한 대표 사례인 MT-DNN에 대해 알아봅시다. MT-DNN의 경우 architecture 자체는 BERT와 비슷하지만 MTL을 수행한다는 점에서 차이가 있습니다. MT-DNN은 다음과 같은 분류로 묶일 수 있는 9가지 GLUE tasks를 수행합니다. 참고로 이번 포스팅은 MT-DNN 모델 자체에 대한 설명을 하는 포스팅이므로, 각 task에 대한 자세한 설명은 생략하겠습니다.
-
Single Sentence Classification : 말 그대로 Single sentence의 class를 분류

-
Text Similarity : Pair of sentences가 주어졌을 때 유사도를 예측하는 일종의 regression task
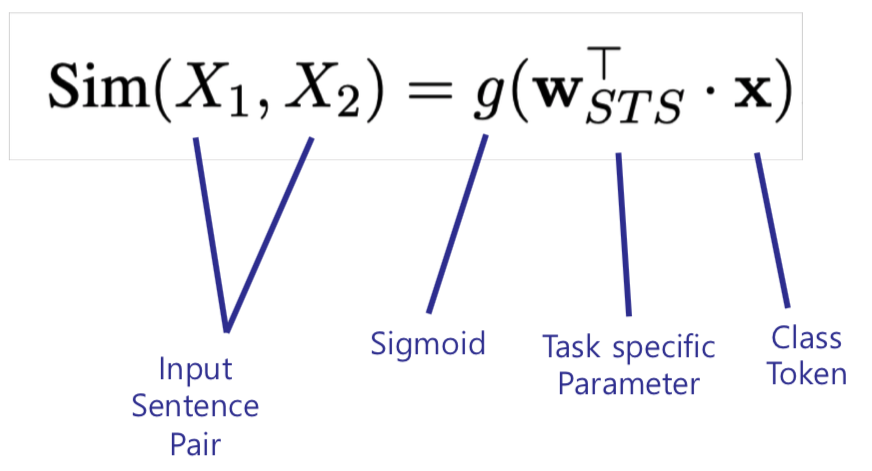
-
Pairwise Text Classification : Pair of sentences 간 관계성을 classify하는 task
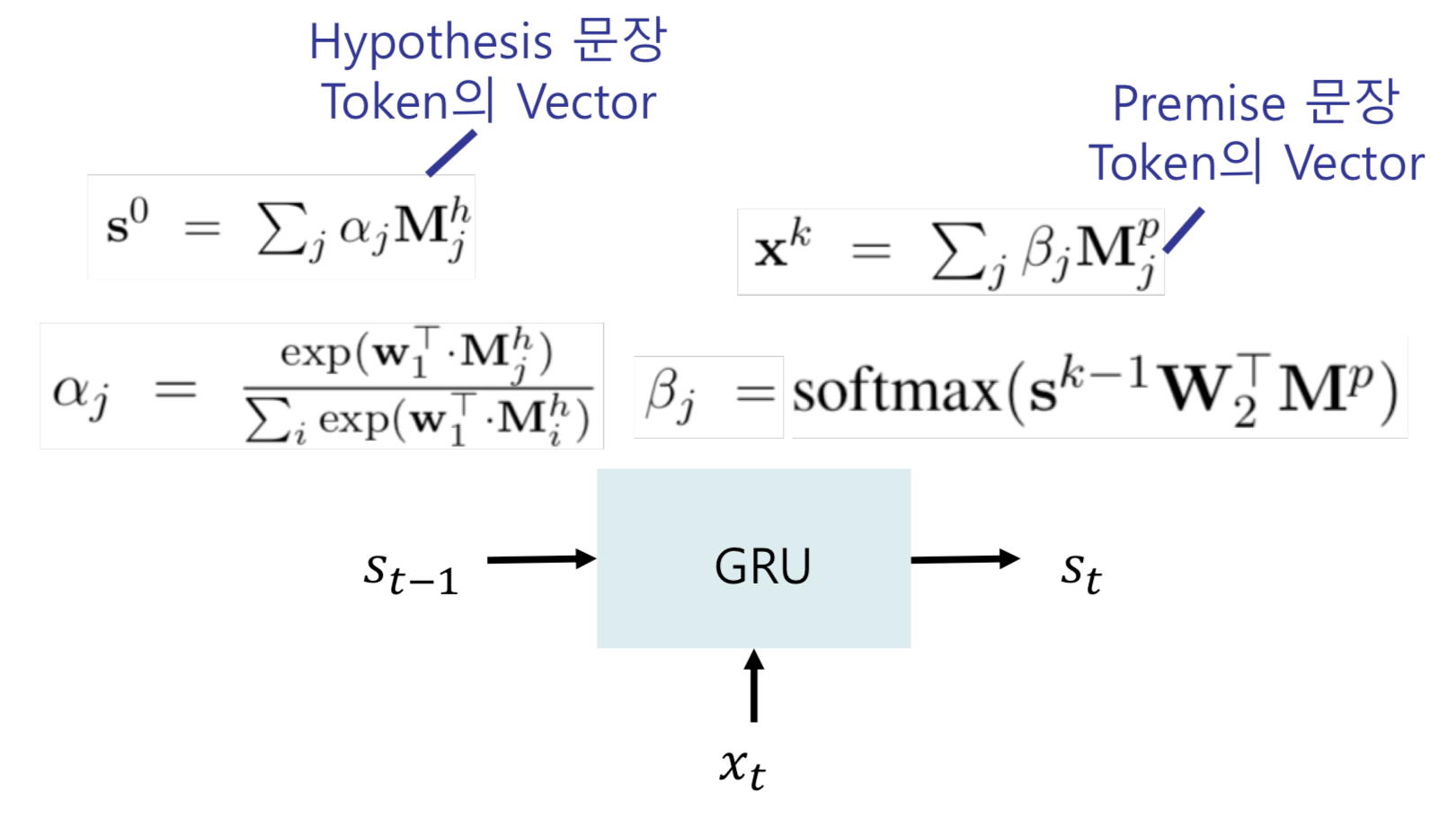

-
Relevance Ranking : Ranking을 통해 질문에 대한 답 등에 올바른 문장을 찾는 task

전체적인 Model Architecture는 아래와 같습니다.
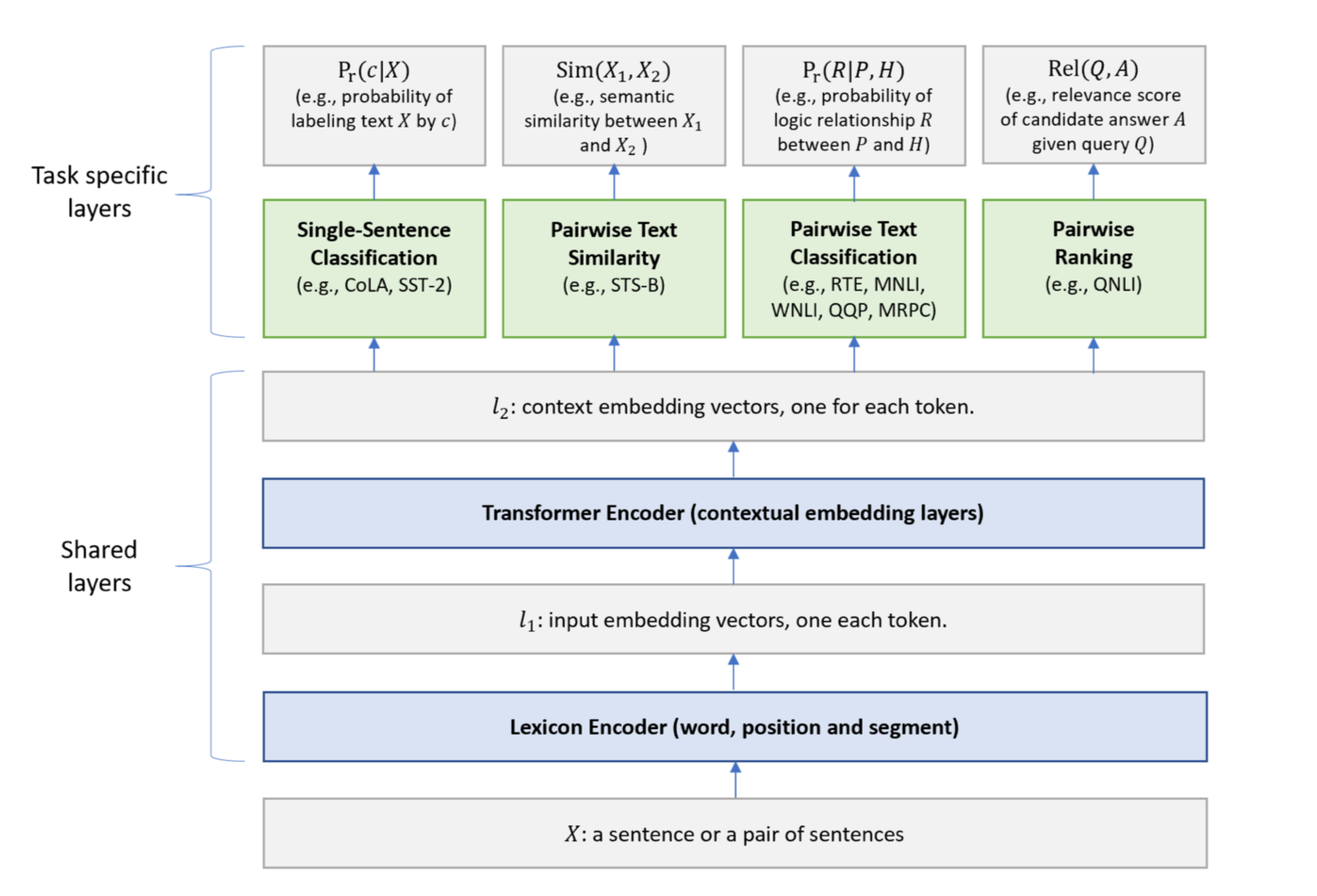
위 구조를 보면 Shared layers 부분은 이전 포스팅에서 여러 차례 설명했던 BERT와 유사합니다. MT-DNN의 특징은 Task-specific layers 에서 드러나게 됩니다. Shared layers에서는 randomly selected 된 데이터 batch에 대해 계속 학습되지만, Task specific layers에서는 각 Task에 해당하는 data로만 학습된다고 합니다. MT-DNN에서 각 task를 학습하는 방법은 윗부분에서 언급했던 식들을 참고하시면 될 것 같습니다.
MT-DNN을 수행하여 나온 결과는 당연히 긍정적이기 때문에(그러니까 논문으로도 나왔겠죠?!) 따로 여기에 명시하지는 않겠습니다. 다만, smaller dataset으로 fine tuning 해야 하는 경우 MT-DNN의 성능이 BERT보다 더더 좋았다고 합니다. 이는 앞서 언급했듯 MTL을 활용하면 각 task에 대한 작은 데이터 크기에도 비교적 강건한 모델이 될 수 있기 때문입니다.
이번 포스팅에서는 MTL와 그 활용안인 MT-DNN에 대해서 알아보았습니다. MTL은 분야를 막론하고 다양하게 쓰일 수 있는 학습 방식이기에 한 번 보실 때 제대로 공부해두시면 아주 좋을 것 같습니다. 조금이라도 도움이 되셨으면 좋겠네요!