[NLP] Seq2Seq with Attention
Seq2Seq with Attention
이번 포스팅에서는 Seq2Seq 모델에 Attention을 결합한 모델을 살펴보도록 하겠습니다. 잠시 Recap 하자면 Seq2Seq 모델은 input과 output 수가 다를 경우 기존 모델만으로 해결하기 어려운 측면이 있어 탄생하게 된 모델로, LSTM과 같은 RNN-based model을 주로 썼다는 점과 입력 시 reverse 하여 넣어주고 Teacher forcing, Beam search 등이 활용된다는 점을 이전 포스팅에서 알아보았습니다. 그렇다면 좀 더 자세히 들어와서, Seq2Seq Encoder-Decoder model에서 Attention이 함께 쓰이면 어떻게 될 지 살펴봅시다.
Encoder-Decoder model with Attention
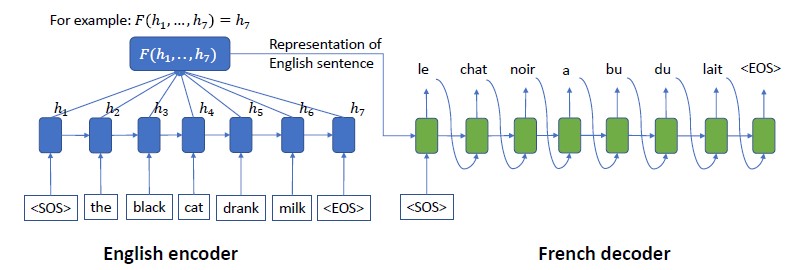
위는 typical한 (Seq2Seq) Encoder-Decoder model의 모습을 나타내고 있습니다. 보통 이러한 모델링을 위해 RNN-based 모델을 활용하는데 여기에는 다음과 같은 단점들이 존재합니다.
- 1) Decoder의 각 time step은 같은 Encoder embedding 에 의존한다
- 2) Encoder embedding은 모든 encoder time step에 대한 정보를 포함할 것이라고 가정되지만, 실상은 그렇지 않을 수 있다
Attention은 이러한 단점을 완화하기 위해 등장합니다. 어떠한 방식으로 Attention이 Seq2Seq 모델에 도움을 줄 수 있을까요?
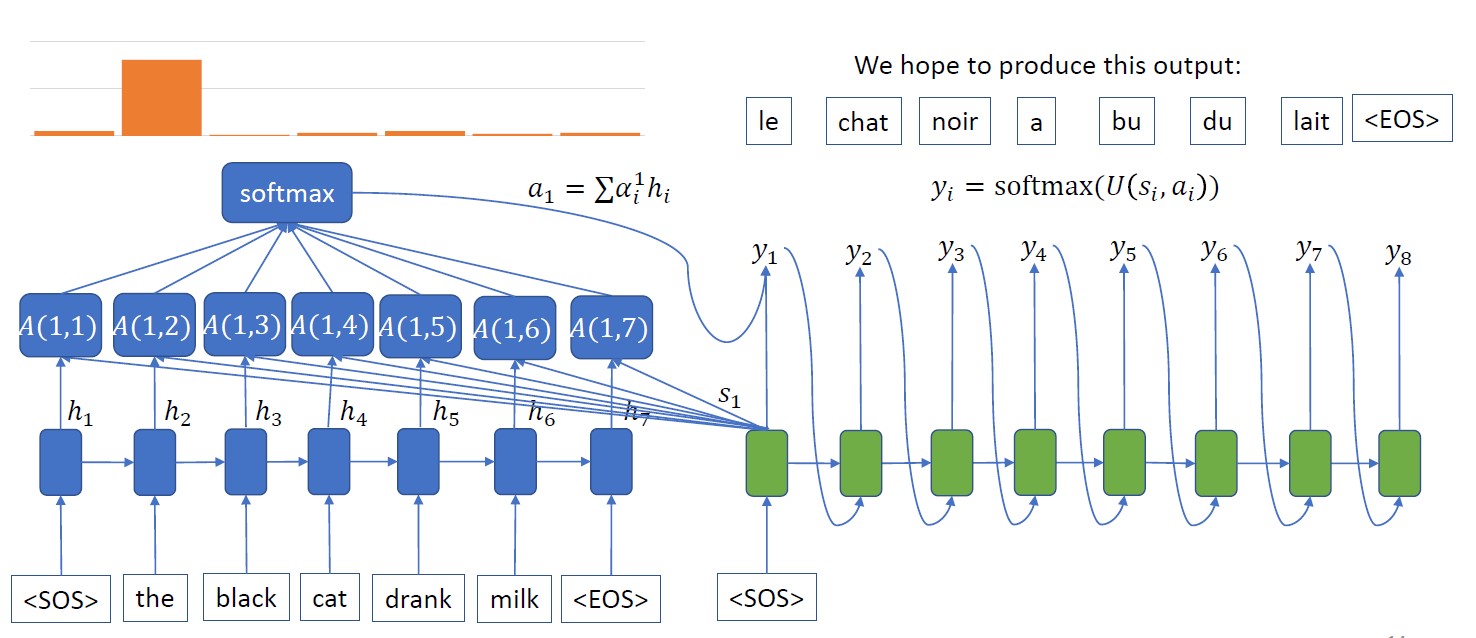
위 그림을 통해 알 수 있듯 Attention을 도입하면 Encoder 파트 input끼리 attention score를 구해서 어느 부분이 더 중요하고 덜 중요한지 파악한 뒤, 그 정보를 각 Decoder time step에 결합해주어 Encoder의 각 time step별 정보를 Decoder에 전달해주게 됩니다. 이렇게 하면 위 단점들 중 1)이 해결됨은 쉽게 알 수 있고, 2)도 Encoder 파트에서 Attention을 결합해 이전 모델보다 time step 별 정보가 더 풍부해져 단점을 완화할 수 있음을 짐작할 수 있습니다. 결국 Decoder 파트에서 기본 뼈대는 RNN-based 모델을 사용하더라도 Attention의 이점을 활용하여 더 나은 result를 낼 수 있게 됩니다. 간단한 결합처럼 보이지만 더 나은 성능을 이끌어낼 수 있다는 점에서 놀랍고 의미있는 연구 같네요! (더 자세한 Attention 및 Transformer 에 대한 설명은 추후 포스팅으로 진행할 예정입니다)
(+) Types of attention
사실 Attention을 계산하는 방식에는 여러가지가 있습니다. 많이 알려져있는 Scaled dot attention, Bahdanau attention 등 여러 방식이 있을 수 있는데, 그것을 간단히 분류해보면 아래와 같습니다.
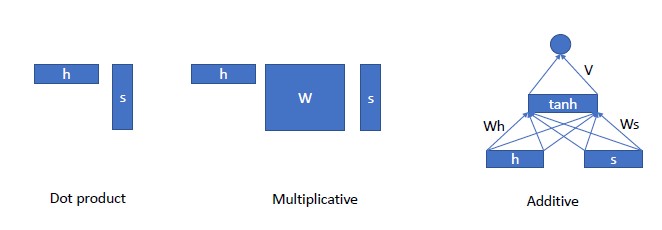
Dot product 형식이 많이 알려진 형식 같고, 그 외 Multiplicative나 Additive 형식으로도 Attention score를 산출해낼 수 있습니다. 어떤 것을 선택할지는 데이터나 모델 구조에 따라 가장 좋은 결과를 낼 수 있는 것으로 선택해주시면 될 것 같습니다.
이번 포스팅에서는 이전 포스팅에서 알아보았던 Seq2Seq 모델에 Attention을 결합하여 좀 더 자세히 살펴보았습니다. Attention 자체에 관한 더 많은 정보는 이후 포스팅에서 알아보도록 하죠!