[NLP] Text classification
Text classification
이번 포스팅에서는 GLUE 벤치마크에 포함된 데이터셋과 관련 tasks를 중심으로 NLP 분야에서 논의되는 여러 Text classification challenge에 대한 overview를 살펴보도록 하겠다.
GLUE benchmark
-
Single-Sequence tasks
- Acceptability judgement : CoLA
- Sentiment classification : SST-2
-
Sequence-Pair tasks
- Paraphrase identification : MRPC, QQP
- Similarity prediction : STS-B
- Natural Language Inference : MNLI, QNLI, RTE, XNLI
Linguistic Acceptability
Linguistic Acceptability는 명칭 그대로 어떤 문장의 문법적 수용가능성 (acceptability)를 판단하는 task이다. 예를 들어 ‘나는 절대 침대를 샀다.’ 라는 예시 문장이 있다고 하자. 이 문장이 입력으로 들어갔을 때 이것이 문법적으로 가능한지를 판단해내는 task가 Linguistic Acceptability 인 것이다. 해당 문장의 경우 당연히 말이 안되기 때문에 ‘불가능’ 이라고 나오도록 모델을 구성하는 것이 목적이다. 문법적인 모순을 찾아내는 능력을 모델에 잘 훈련시키는 것이 task의 핵심이다. 물론 모든 linguistic examples가 acceptability classification task에 적합한 것은 아니므로 이러한 부분도 잘 고려되어야겠다.
Linguistic Acceptability의 벤치마크로 쓰이는 데이터로는 CoLA가 있으며, 이것은 약 11k 정도의 영어 문장들이 문법적으로 수용가능한지, 아닌지가 labeling 되어 있는 데이터셋이다. Training, Development, Test 셋으로 나누어져있으며, labels는 original authors에 의해 annotate되었다고 한다.
Sentiment classification
사실 감성분석은 너무나도 잘 알려져있고 직관적인 NLP task 중 하나이다. 말 그대로 어떤 입력이 주어졌을 때 그것이 긍정인지 부정인지 판단하는 태스크이다. 예를 들어, 입력으로 ‘나는 그 영화가 정말 재미없었어.’ 가 들어가면 출력으로 ‘부정’이 나오도록 하는 것이다.
이 task의 벤치마크로 쓰이는 데이터로는 SST-2, IMDB 데이터 등이 있으며, 개인적으로는 IMDB 데이터가 접근도 쉽고 예시 코드도 많아서 연습용으로 쓰기는 좋았던 것 같다. 감성분석 task 는 비교적 친근한 task이므로 이렇게 간단히 언급만 하고 넘어가도록 하겠다.
Paraphrase identification
Paraphrase identification이란 두 텍스트가 서로 비슷한 의미를 지니고 있는지를 판단하는 task이다. 그래서 보통 label이 same / not same 이런 식으로 annotate 된다.
이 task의 벤치마크 데이터로는 MRPC, QQP 등이 있다. 우선 MRPC는 Microsoft Research Paraphrase Corpus로, 총 5800여개의 문장쌍을 포함하고 있다. 확실히 다른 데이터셋에 비해 크기가 좀 작기 때문에 해당 데이터로 뭔가 거대한 모델을 구상하기에는 어려움이 있지만, sparse data 시험용으로 쓰이기에는 적합하다는 의의가 있다. QQP의 경우 Quora Question Paraphrases로, MRPC와 같이 same / not same으로 label이 달려있으며 크기는 총 400k 정도 된다. 확실히 MRPC보다는 크기 때문에 두 데이터에 모두 잘 적용되는 모델을 잘 찾으면 좋을 듯 하다.
Similarity prediction
Similarity prediction은 문장 pairs가 유사한지의 degree를 판단하는 task이다. 유사도를 보려고 한다는 점에서 앞서 언급한 Paraphrase identification과 헷갈릴 수 있지만, PI는 단순히 same / not same 만 판단하는데 비해 STS 혹은 SP는 그 ‘정도’를 파악한다는 차이점이 있다. Degree는 주로 1~5의 스케일로 상정된다.
이 task의 벤치마크 데이터에는 STS-B가 있는데, 이것은 뉴스 헤드라인이나 이미지 캡션 등의 source에서 뽑아진 sentence pairs로 구성되어 있다. Similarity metric으로는 주로 Pearson/Spearman correlation coefficient가 쓰이며 크기는 총 약 10k 정도 된다.
Natural Language Inference (NLI)
NLI는 한국말로 ‘자연어 추론’ 이라는 task로, 전제(Premise)와 가설(Hypothesis)을 입력으로 받아 그 둘 간의 관계성 (Entailment / Contradiction / Neutral)을 판단한다. NLI는 사실 자연어 형태의 문장을 ‘이해’하는 Natural Language Understanding (NLU) 의 기반이 되는 task로서, NLU는 기계를 접목하여 서비스를 적용하는 측면에서 매우 중요한 역할을 하기 때문에 NLI 또한 중요한 task라고 볼 수 있겠다.
예를 들어서 좀 더 구체적으로 살펴보면, Premise로 ‘나는 지금 친구와 함께 피자랑 파스타를 먹고 있다.’ 가 들어가고, Hypothesis로 ‘나는 이탈리안 음식을 먹는다.’ 가 입력되었다고 가정하자. 그렇다면 이 두 문장 간 관계는 Entailment라고 판단할 수 있고, 모델링의 결과 Entailment가 산출되어야 한다.
이 task의 벤치마크 데이터로는 SNLI, MNLI, QNLI, XNLI 등이 있으며 주로 Entailment / Contradiction / Neutral 혹은 Entailment / Not Entailment 와 같은 식으로 label이 구성된다. 우선 SNLI 데이터는 약 570k 정도의 human-written 영어 문장쌍들을 포함하고 있고 labels가 manually annotated 되었다. 하지만 이미지 캡션이라는 limited domain 한계로 인해 MNLI (Multi-Genre NLI)도 많이 활용하며 이것은 좀 더 다양한 written / spoken speech 데이터를 총 약 430k 정도의 크기로 가지고 있다. XNLI와 QNLI도 SNLI나 MNLI와 유사한 목적을 지닌 데이터셋이나, XNLI는 15개의 language로 구성되어 있다는 점과 QNLI는 question 형태라는 점에서 다소 차이가 있다고 할 수 있다.
FYI) SuperGLUE
참고로 GLUE 보다 좀 더 심화된 NLU tasks를 모은 벤치마크로 SuperGLUE라는 것도 존재한다. GLUE와는 데이터셋 구성이 약간 다르며, BiLSTM을 baseline으로 쓴 GLUE와 달리 SuperGLUE는 BERT를 baseline으로 사용한다. NLP 분야가 빠르게 발전하고 task들도 높은 정확도를 달성하며 해결해나가고 있는 추세이므로 좀 더 어렵고, 복잡한 tasks 및 데이터가 다뤄지는 흐름을 잘 따라갈 수 있도록 해야한다.
Summary
위에서 언급했던 여러 tasks를 표로 정리해보면 아래와 같다.
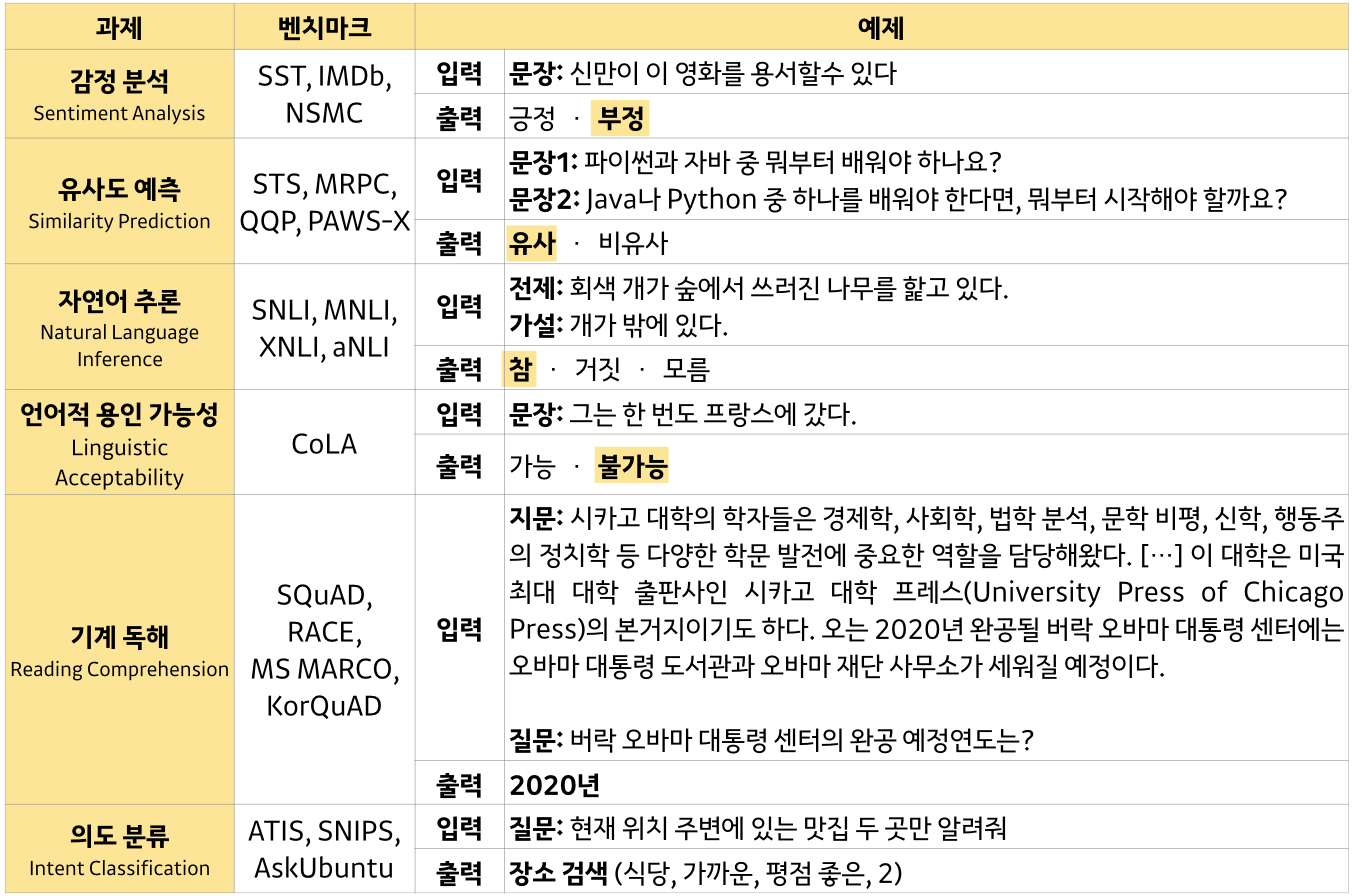
이번 포스팅에서 언급하지 않았던 기계 독해 (MRC) 부분은 다음 포스팅에서 살펴보도록 하자.