[NLP] Transformer - Details
Transformer details
이번 포스팅에서는 Attention is all you need 논문 리뷰에서 살펴보았던 Transformer의 좀 더 구체적인 디테일에 대해 다뤄보도록 하겠습니다. 구조나 지난 포스팅에서는 스킵했던 Residual connection, Layer normalization 등에 대해 알아봅시다(FFN나 Positional Encoding 등은 너무 기본이거나 이미 설명한 것이기에 생략하겠습니다). 참고로 설명에 나오는 파라미터 세팅같은 것은 Attention is all you need 논문을 따르도록 하겠습니다.
Residual Connection
Residual connection 은 간단히 표현하면 Input을 다시 더해주는 과정입니다. 좀 모호하죠? 그림을 살펴봅시다.
![]()
Transformer를 기준으로 보자면 위의 X는 Input(embedding) 값, F(x)는 Multi-Head Attention과 같은 (sub)layer를 의미합니다. 이것을 보면 Input을 다시 더해주는 것이라는 위의 설명이 무엇인지 대충 감이 오시죠?
그렇다면 왜 Residual connection을 시행하는 것일까요? 일반적으로 Residual connection은 Gradient Vanishing 과 같은 문제를 완화하기 위한 테크니컬 툴로 이용됩니다. 위 식을 보시면 알 수 있듯 X를 그대로 다시 더해주면 미분 시 이것 덕분에 Gradient Vanishing 이 좀 덜해질 수 있는 것이죠. Transformer에서도 이것을 활용합니다.

Layer Normalization
Layer normalization은 Multi-Head Attention 과 같은 Transformer의 Sublayer를 통과하고 Residual connection까지 거친 뒤 적용됩니다. LN은 Residual connection Output을 기준으로 d 차원(논문에서는 d=512)에 대해 평균 및 분산을 구하고, 이후 2개의 과정을 거쳐 수행됩니다.

-
1) 일단 우리가 일반적으로 아는 정규화(Normalization)을 수행합니다
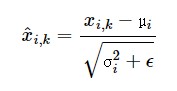
-
2) Gamma(초기값: 1) & Beta(초기값: 0)라는 파라미터를 도입하여 최종 LN 값을 도출합니다
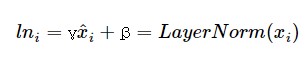
확실히 이렇게 Layer Normalization을 진행하면 성능이 높아질 수 있겠죠?
1. Encoder ver. Transformer
Encoder 입장에서의 Transformer를 먼저 살펴보도록 하죠. 일단 그림으로 표현하자면 아래와 같습니다.
![]()
크게 보자면 이전 포스팅에서 배웠던 Multi-Head Attention 구조를 지나 Residual connection + Layer normalization을 하고, Feed Forward Network을 지난 뒤 다시 Residual connection + Layer normalization을 하면 Encoder가 완성됩니다. 이 Encoder를 여러개 쌓아놓으면 그게 결국 Encoder ver. Transformer가 되는데, 논문에서는 6개를 쌓았다고 하네요.
Multi-Head Attention 자체는 이미 앞선 포스팅에서 설명을 드렸기 때문에 간단하게 recap만 하겠습니다. 사실 여기에서 쓰이는 것은 Multi-Head SELF Attention 인데, 이것은 Multi-Head Attention과 구조는 동일하나 Q,K,V 측면에 있어서 명칭 그대로 자기자신 에 attention을 준다는 특징이 존재합니다.
-
1) Input X가 들어오면 각 파라미터 W_Q, W_K, W_V를 곱해주어 Query, Key, Value를 구해주는데 각 파라미터의 dimension은 d*(d/# of heads) 가 됩니다. 논문에서는 d=512, # of heads를 8로 가정해주었습니다. 즉, Input에 가중치 행렬을 곱해줘서 8개의 head를 통해 64 dimension을 가지는 Query, Key, Value를 구한다는 것입니다.

-
2) 이렇게 Q,K,V를 구하고 나서는 Scaled-dot product attention 식을 통해 Attention score를 도출합니다.



-
3) 위 과정을 # of heads 만큼 반복하고, 산출된 matrices를 concatenate한 뒤, Output을 위한 파라미터 W_O를 곱해주면 결론적으로 Multi-Head Attention matrix를 output으로 내게 됩니다. 이렇게 최종적으로 도출되는 Multi-Head Attention matrix의 dimension은 Length of sequence*d, 즉 Input X의 차원과 동일합니다.
![]()
![]()
(+) 참고로 [PAD] 와 같은 토큰의 경우 별 의미가 없기 때문에 Attention score 계산 시 -Inf 에 가까운 값을 주어 Softmax 통과 후 0에 가까운 값이 되도록 Masking 합니다.
이렇게 Multi-Head Attention sublayer를 통과하고 나서는 RC+LN 및 FFN을 통과하여 Encoder 값이 산출되고, 이것을 논문 기준 6번 반복하면 Encoder ver. Transformer가 완성됩니다.
2. Decoder ver. Transformer
이제부터는 Decoder 입장에서의 Transformer를 살펴봅시다.

사실 이것도 전체적인 구조는 Encoder ver.과 크게 다르지 않습니다. Multi-Head Attention이나 FFN, RC+LN은 위에서 이미 설명했으므로 여기서는 첫번째 Sublayer인 Masked Multi-Head Self Attention에 대해 알아봅시다.
Masked Multi-Head Self Attention 이것도 Masking 개념이 들어갔다는 점이 특징이고, Multi-Head Attention 구조는 동일합니다. 사실 이 Masking 부분도 Attention is all you need 나 BERT 포스팅에서 이미 설명하기는 했습니다만, 다시 한 번 recap 해보도록 하죠. Machine Translation 을 예시로 살펴봅시다. 입력으로 ‘나는 학생입니다’ 가 들어가고 출력으로 ‘I am student’ 가 나와야 한다고 가정합시다. 이 때, ‘I am student’ 중 ‘am’ 을 도출해내기 위해 ‘student’_를 참고하는 것이 말이 될까요? 실제 번역에서는 순차적으로 입력이 이루어지기 때문에 현실에 적용하자면 우리는 _‘am’ 을 도출해야하는 시점에 ‘student’ 라는 단어는 모르는 상태입니다. 그러므로 Transformer 구조 내에서 training 을 해줄 때도 현재 시점 이후의 단어는 참고하지 못하도록 Masking 해주어야 합니다. 이를 위해 Attention Score를 도출하는 데 있어 Look-Ahead Mask라는 것을 씌워 Masking 해주면 됩니다. Look-Ahead Mask를 결합하여 도출된 Attention Score는 아래와 같습니다.

Masked Multi-Head Self Attention은 위처럼 Masking을 도입하고 나머지는 그냥 Multi-Head Attention 구조대로 적용해주면 됩니다.
Masked Multi-Head Self Attention 이후의 Sublayers는 Multi-Head Attention와 FFN 등으로 Encoder ver.과 유사합니다.
3. Encoder-Decoder ver. Transformer
Encoder-Decoder ver. Transformer는 Encoder ver.과 Decoder ver.을 연결한 것으로, 위에서 배웠던 것들을 종합한 버전입니다.
![]()
이미 위 Sections에서 다 다뤘던 구조들이라 추가적으로 설명할 것은 없으나, Decoder 쪽 Multi-Head Attention 파트에서 Query로 Decoder 행렬이 들어가고, Key, Value로는 Encoder 행렬이 들어간다는 점에서 Q,K,V로 모두 같은 값이 들어가는 Encoder ver.과 차이가 있다는 점만 유의해주시면 됩니다.
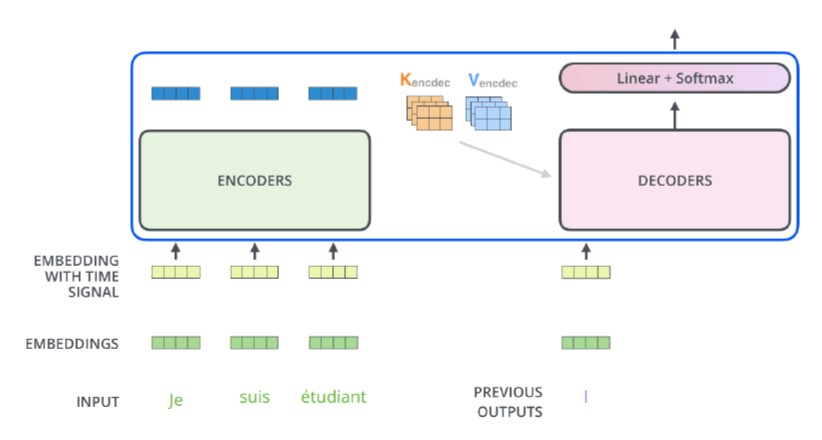
이번 포스팅을 통해 Transformer를 보다 자세히 뜯어보았습니다. 이해에 도움이 되셨으면 좋겠네요!