[NLP] Global vs. Local Attention
Global vs. Local Attention
이번 포스팅에서는 Global Attention과 Local Attention에 대해 알아보도록 하자.
Global Attention
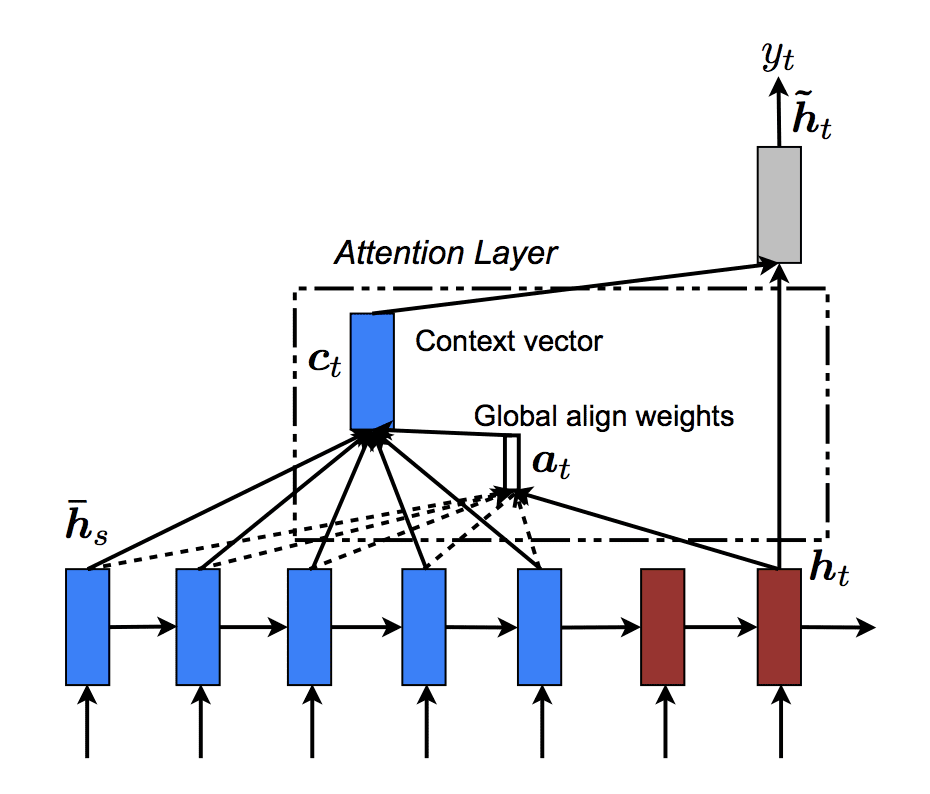
Global Attention은 Encoder에 있는 모든 hidden state를 고려하여 만들어진 모델로, alignment score를 아래 식처럼 구한 후(단, Bahdanau attention 등을 쓰려면 식이 약간 달라질 수 있음) source hidden state에 a_t를 이용한 가중평균을 context vector로 만들게 되는 것이다. \(a_{t} = softmax(W_{a}h_{t})\) 여기서 포인트는 ‘모든’ hidden state를 고려한다는 것이다. 이러한 Global Attention model은 computationally expensive 할 수 있다는 단점을 지니고 있다.
Local Attention
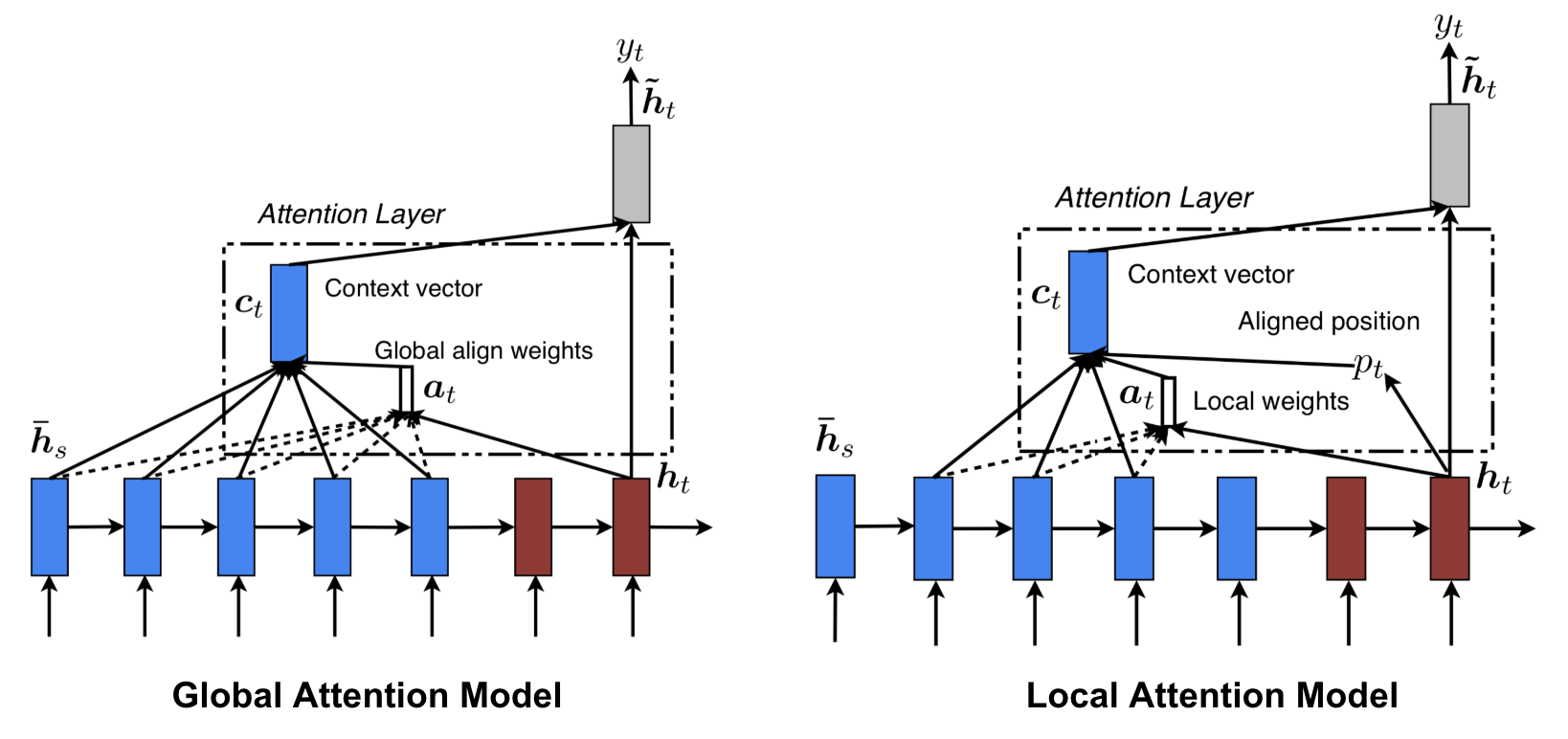
Local Attention은 Global Attention 과 달리 ‘일부’ hidden state만 활용한다. 이렇게 일부만 고려하는 이유 중 하나는 앞서 언급했듯 Global Attention처럼 ‘모두’를 활용하려면 computationally inefficient 해질 수 있기 때문이다. NLP 분야의 예시를 들면 엄청나게 긴 문장이 input으로 들어온 경우 문장은 길지만 그것을 represent하는 핵심 keyword는 짧을 수 있다. 그렇게 되면 Global Attention model을 써서 데이터를 분석하는 건 일종의 낭비일 수 있다는 것이다. 따라서 Local Attention에서는 타겟 당 일부 aligned position만을 본다.
Global vs. Local을 나타내는 아래 그림과 결부하여 과정을 조금만 더 살펴보면,
- 1) 현재의 타겟 단어와 관련하여 attend할 aligned position을 예측한다
- 2) 앞서 구한 aligned position을 중심으로 그 주변 window source들을 context vector 산출에 사용한다
위와 같이 정리해볼 수 있겠다.
FYI) Soft vs. Hard Attention
참고로, Global vs. Local 외 Soft vs. Hard Attention도 있다. 이는 Global vs. Local과 유사한데, 일단 Soft Attention의 경우 Global Attention과 거의 유사하다. 반면 Hard Attention의 경우 Local Attention과는 약간 다른데, Hard는 타겟에 대해 attend 할 딱 한 부분만 정해서 사용한다. Local Attention은 Soft 와 Hard 의 혼용 정도로 이해하면 될 것 같다.
작동원리에서 알 수 있듯 Soft의 경우 모델이 미분가능하고 smooth하지만 computationally expensive 할 수 있다. Hard의 경우는 딱 하나만 선택하는 것이기 때문에 빠르긴 하지만 미분이 불가능하고 Monte Carlo 방법 등을 쓸 때 커지는 분산을 조금이라도 줄이기 위해 variance reduction 테크닉 등 여러 복잡한 기술들이 요구된다는 단점이 있다. 그래서 보통 Soft Attention을 많이 사용하나, Hard Attention이 해석력이나 다른 probabilistic model과의 결합 측면 등에서 장점을 보이고 있기 때문에 Hard Attention을 보완한 버전인 Variational Attention 등도 등장하였다. 연구자가 어떤 분석을 하고자 하는지에 따라 신중히 모델을 선택하면 될 듯 하다.