[Paper Review] Text Understanding with the Attention Sum Reader Network
Text Understanding with the Attention Sum Reader Network
Introduction
CNN, Daily mail news data 및 Children’s Book Test 와 같은 대규모 Cloze-style 의 컨텍스트 질문-대답 데이터셋이 4~5년 전 쯤 소개되었습니다. 우리는 이러한 대규모 데이터셋 덕분에 Text understanding task 를 딥러닝 기법과 연관짓기가 쉬워졌습니다. 본 논문은 이러한 Cloze-style question 을 활용하여 Text understanding을 하는 비교적 간단한 딥러닝 / 어텐션 모델을 제시합니다. 이번 포스팅에서는 이 논문의 review를 통해 여기서 제시하는 Attention Sum Reader Network 가 무엇인지에 대해 알아봅시다.
Cloze-style question
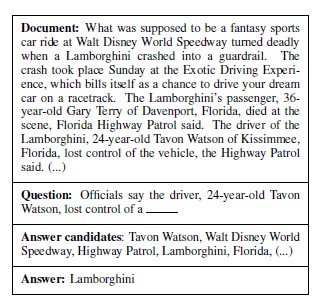
Cloze-style questions는 문장에서 구를 삭제하여 형성된 질문입니다.
Text understanding을 테스트하는 한 가지 방법은 텍스트에서 답을 추론할 수 있는 질문을 하고 답을 잘 맞히는 지 보는 것입니다. Cloze-style questions는 그러한 질문에 잘 쓰이는 question form 입니다.
Task description
궁극적인 Task는 질문과 함께 제공되는 컨텍스트 문서의 이해에 따라 답이 달라지는 Cloze-style questions에 대해 대답을 하는 것입니다. 모델에는 정답 후보들도 함께 제공됩니다.
- Dataset : CNN & Daily Mail & Children’s Book Test
기존 LSTM 모델은 동사와 전치사를 예측하는 데 있어 인간 수준의 성능을 가지고 있지만, Named entities와 Common nouns에 대해서는 성능이 다소 떨어집니다. 따라서 본 논문은 Named Entities & _Common nouns_를 예측하는 데만 초점을 맞추고 있습니다.
Model - Attention Sum Reader
Attention Sum Reader는 답변이 컨텍스트 문서에 포함된 단어라는 사실을 활용할 수 있도록 제작되었습니다. 이 모델에는 분명한 장점과 단점이 있습니다. 위에서 언급한 설정 내에서 정답을 선택하는 성능은 탁월하지만, 문서에 포함되지 않은 정답은 생성할 수 없다는 점이 그것입니다.
Overall Architecture_는 다음과 같습니다. (Note: _Bidirectional)
- 쿼리의 벡터 임베딩 계산
- 전체 문서의 맥락을 고려한 각 개별 단어의 벡터 임베딩 계산 (Contextual embedding)
- Question embedding과 Contextual embedding 간 dot product 를 사용하여 가장 가능성이 높은 답변을 선택
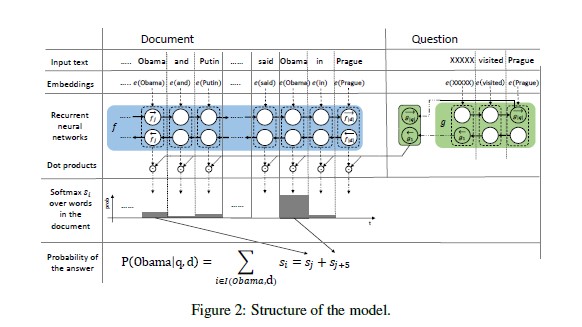
Detailed procedure :
- Word Embedding : 단어를 벡터 표현으로 변환
- First Encoder (f ) : 문서의 모든 단어를 전체 문서의 맥락을 고려하여 encoding (Document Encoder -> Contextual embedding)
- Second Encoder (g ) : 쿼리를 output of first encdoer와 동일한 차원의 fixed length representation으로 변환
- Similarity : 문서의 모든 단어에 대한 가중치를 Contextual embedding 및 Query embedding의 dot product 로 계산 -> 이 가중치는 attention over document 로 볼 수 있음
Formula :
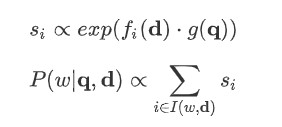
Pointer sum attention :
위의 I(w,d)는 w가 document d 내에서 등장한 모든 위치 집합을 나타냅니다. 이 mechanism은 Contextual document에서 attention을 discrete tokens 에 대한 pointer_로 사용하고 모든 occurrences에 걸쳐 단어의 attention을 direct sum하기 때문에 _pointer sum attention 이라고 불립니다.
이것은 attention이 단어들의 representations를 잘 섞어서 새로운 embedding vector를 생성해내는 Seq2Seq models 내 일반적인 attention 사용 방법과는 다소 다르다고 할 수 있습니다.
Model Comparison
1) Attentive and Impatient Readers
Document d의 fixed length representation _r_은 다음과 같습니다 :
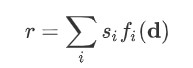
그리고 Joint query & document embedding m은 r 과 query embedding g(q)의 비선형 함수가 됩니다. 이 Joint embedding m은 결국 dot product 를 기준으로 모든 candidate answers과 비교되며, 결국 최종 score는 Softmax 에 의해 normalize 됩니다.
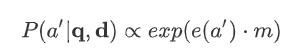
본 논문에서 소개하는 Attentive Sum Reader_는 individual representations 에 대한 weighted sum 과 같은 복잡한 식을 사용하지 않고 compute된 attention을 _바로 사용하여 context 에서 정답을 선택한다는 점에서 위 모델과 차이가 있습니다.
2) Chen et al. (2016)
단순한 dot product 대신 bilinear term 을 사용합니다.
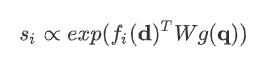
그 외 다른 세팅들은 위 1) 과 유사합니다.
ETC. - Dynamic Entity Representation, Pointer Networks ….
Experiment Results
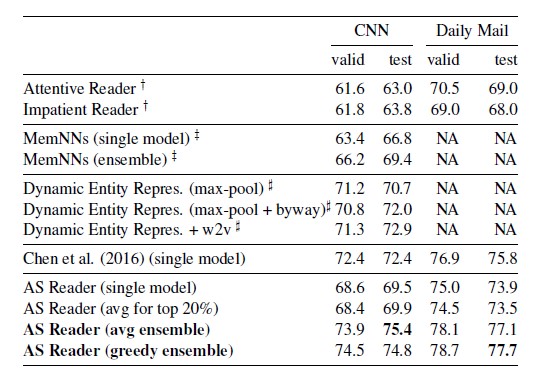
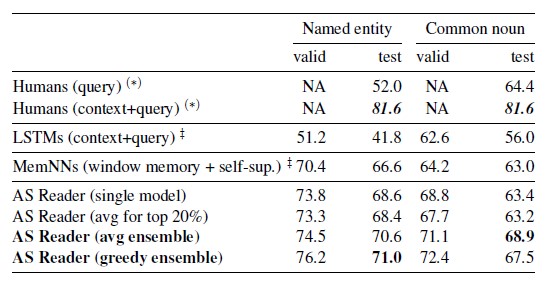
본 포스팅에서는 핵심 모델인 Attention Sum Reader Network 를 설명하는 데 초점을 맞추었으니, 그 외 다양한 타 모델들과의 comparison은 논문 에서 직접 확인해보시길 추천드립니다.