[Paper Review] Attention is all you need
Attention is all you need (2017)
이번 포스팅에서는 NLP를 비롯한 분야의 판도를 뒤집어놓은 유명한 논문, Attention is all you need (2017) 에 대한 Paper review를 해보도록 하겠습니다. 필자가 생각하기에 중요하다고 여겨지는 부분 위주로 summary 한 것이니 Attention을 알아보고자 하시는 분이라면 원 논문을 꼭 다 읽어보시는 것을 추천드립니다.
(** 제가 읽고 직접 쓴 review 이기 때문에 중간에 틀린 점이 있을 수 있습니다! 혹시 발견하신다면 알려주세요ㅜㅜ)
1. Motivation
Attention이라는 개념이 등장하기 전까지는 보통 Sequential data를 다룰 때 RNN, LSTM과 같은 Recurrent model을 주로 활용하였습니다. 하지만 이러한 모델에는 다소 치명적인 단점이 있었는데, 그것은 바로 Long-term dependency problem 입니다. 앞선 RNN 포스팅에서도 잠깐 언급했었지만, RNN과 같은 모델은 요소 간 거리가 멀어질수록 그 정보값이 잘 유지되지 못하는 특징이 있습니다.
예를 들어, ‘나는 언어학을 전공하였고 현재 대학원에서는 딥러닝을 공부하고 있는데, 그래서인지 특히나 NLP 분야에 관심이 가는 것 같아.’ 라는 예시 문장이 있고 ‘NLP’ 이라는 부분을 맞히는 모델을 짜고 싶다고 가정합시다. Long-term dependency problem 이란 ‘NLP’라는 답을 나오도록 하는 데에 ‘언어학’ 이라는 단어가 중요한 역할을 함에도 불구하고 ‘딥러닝’ 이라는 단어가 더 가까워 영향을 많이 주기 때문에 ‘NLP’ 대신 ‘이미지’ 와 같은 엉뚱한 답이 산출될 수 있다는 문제점을 의미합니다.
Attention mechanism 은 이러한 단점을 보완해줄 수 있는 모델로, 입력 정보중 어떤 것을 중점적으로 참고 해야할지를 통해 모델링을 진행하는 구조입니다. 그럼 이제부터 그 구조와 원리에 대해 살펴보도록 합시다.
2. Multi-Head Attention
일단 Self-Attention의 전체적인 구조를 보기에 앞서 그 구성요소인 Multi-Head Attention이란 무엇인지 알아보도록 하겠습니다.
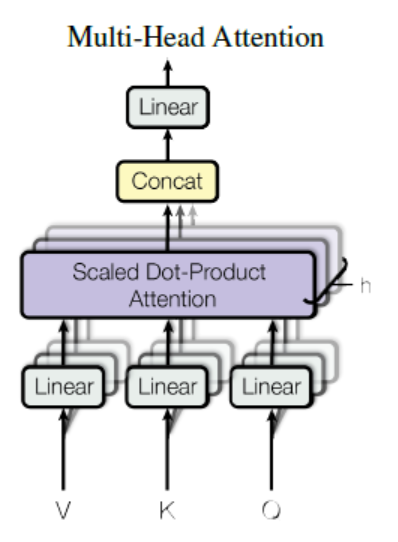

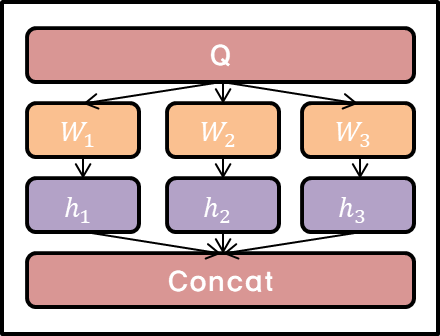
일단 Multi-Head Attention은 위와 같은 구조를 보이고 있습니다. 그럼 저기서 중심이 되는 것으로 추정되는 Scaled Dot-Product Attention이란 무엇일까요?
-
Scaled Dot-Product Attention :
Scaled Dot-Product Attention 이란 말 그대로 Dot-product 값을 Scaling 하여 Attention score를 구했다는 것을 의미합니다. 일단 그림과 식을 살펴봅시다.
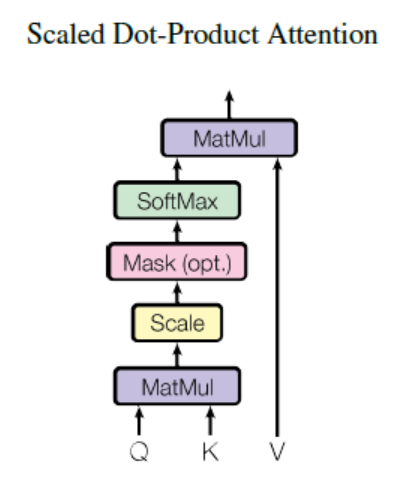
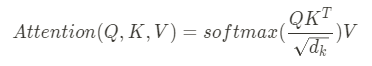
위 식에서 알 수 있듯, Attention은 Q와 K의 dot product를 취해준 뒤 root(d_k)로 일종의 Scaling을 해주고 거기에 Softmax를 씌워 V에 가중합을 해준 형태를 보이고 있습니다. 앞서 설명한 바와 일치하는 흐름을 보이고 있습니다. 그렇다면 여기서 Q, K, V 는 각각 무엇일까요?
- Q (Query) : 영향을 ‘받는’ 단어를 나타내는 변수
- K (Key) : 영향을 ‘주는’ 단어를 나타내는 변수
- V (Value) : 영향에 대한 가중치 (weight)
NLP 예시를 들어 그림으로 설명하면 아래와 같습니다.
사실 이 부분은 저도 이해하는데 꽤 애를 먹었던 파트입니다. 따라서 좀 더 자세한 설명을 원하시는 분들은 다음 이 링크를 참조하시기 바랍니다.
이제 Q, K, V 에 대해 알아보았으니 다시 Scaled Dot-Product Attention을 보면, 결국 이것은 영향을 받는 변수와 주는 변수 간 일종의 유사도_를 dot product 로 측정하여 Softmax를 취하고(일종의 _weight 으로 변환) 그것을 V에 곱해줌으로써 서로의 연관성 정도를 Attention score 라는 값으로 산출해주는 것을 의미한다고 볼 수 있습니다. 참고로 Scaling 은 dot product 값이 커질수록 Softmax 함수의 기울기가 작게 변하는 현상을 완화하기 위한 technical 한 장치라고 합니다.
Scaled Dot-Product Attention의 대략적인 모습을 그림으로 표현하면 (Generalized 된 모델 표현은 아니므로 그냥 흐름만 이해해주세요) 아래와 같습니다.

자 그렇다면 다시 Multi-Head Attention으로 돌아와서, 구조를 위와 같이 Multi-head로 쪼개는 이유는 무엇일까요? 구현 성능 측면에서의 이유라고 합니다. 즉, Q, K, V에 대해 각각 다른 linear projections를 h개 쪼개 수행하고 그 이후 concat 해서 Multi-Head Attention을 구하는 게 더 좋은 performance를 지닌다는 뜻입니다. 그리고 Parallelization이 가능케한다는 점에서도 의미가 있는 듯 합니다. 이를 좀 더 구체적으로 식으로 표현해보면 다음과 같습니다.

(NOTE: Multi-Head Attention에 대한 자세한 디테일은 다른 포스팅을 참조해주세요!)
3. Attention in Encoder-Decoder architecture
일단 그림부터 살펴봅시다.

위 그림은 Encoder-Decoder Attention layer 의 구조를 나타낸 것입니다. 참고로 Encoder만 있는 구조, Decoder만 있는 구조를 따로 다루는 케이스도 있으나 여기서는 둘을 합친 버전만 논의해보도록 하겠습니다. 이 외의 자세한 설명은 다른 포스팅을 참조해주세요! 구조를 보면 이미 우리가 앞서 배운 Multi-Head Attention이 포함되어 있고 부가적으로 Feed-forward 부분과 Layer normalization, Residual connection 등이 적용되어있음을 알 수 있습니다. Feed-forward는 딥러닝의 기본이므로 다들 아실거라고 가정하고, Layer normalization이나 Residual connection은 다소 technical 한 부분이라 이번 포스팅에서는 다루지 않고 다음에 기회가 되면 더 자세하게 논의해보도록 하겠습니다.
구조를 보면 Query는 이전 decoder layer에서 가져오고 Key와 Value는 encoder의 output에서 가져옵니다. 따라서 decoder의 모든 position에서 input sequence에 attend 할 수 있습니다. 즉, encoder output의 모든 position에 attend 할 수 있다는 뜻입니다. Query가 decoder layer의 output인 이유는 Query 그 자체가 condition이기 때문입니다. 더 자세히 설명하자면, 우리가 이러한 decoder value를 가지고 있을 때 어떤 것을 output으로 뱉는 것이 가장 적절한가? 에 대한 답을 내기 위해 작동하는 모델인 것입니다.
이 때, Decoder 파트에서는 오직 previous positions만을 참조하도록 만들어져야 합니다(그 이후의 값을 참조하여 output을 낸다는 것은 말이 안됨). 따라서 이러한 auto-regressive property를 유지할 수 있도록 모델이 짜여져야 하는데, 여기서는 이를 위해 Masking 이라는 것을 수행합니다. 예를 들어 우리가 i-th output을 내고싶으면 i-th position 이후의 모든 positions를 i-th position의 attention value를 구할 때 masking 해준다는 것입니다. 참고로, 기술적으로 masking out 한다는 것은 Softmax의 input 값을 negative infinity로 준다는 것을 의미합니다.
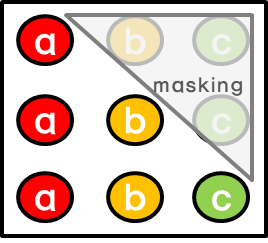
참고로, SELF-Attention 이란 Attention은 Attention이나 Q,K,V가 같아서 말그대로 자기자신 에 대해 attend하는 버전을 의미합니다.
4. Transformer
그렇다면 Attention mechanism을 활용한 대망의 모델, Transformer 는 어떤 것일까요?
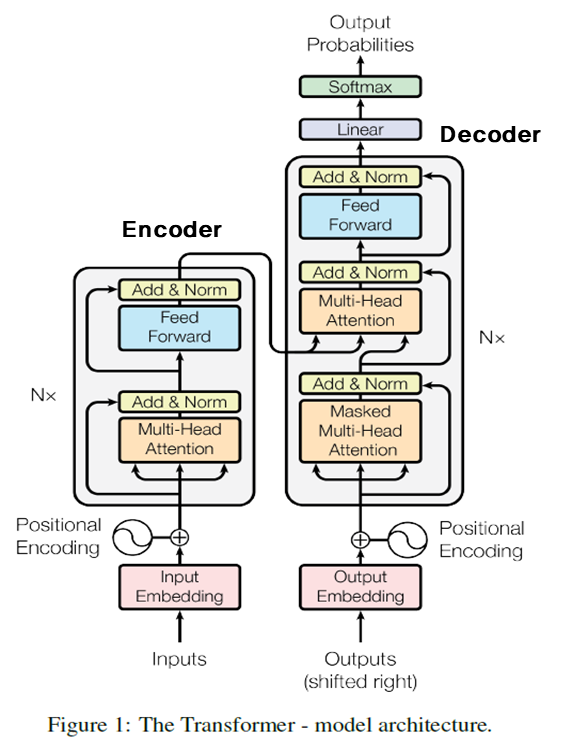
위 구조를 보면 알 수 있듯, Transformer는 Self-Attention 구조에 Positional Encoding과 같은 부분을 결합하여 만들어진 모델입니다. 사실 유명한 NLP 모델 중 하나인 BERT 가 이러한 Transformer를 차용한 모델이기 때문에 이번 포스팅에서는 PE 부분만 간단히 보고 BERT를 다루는 다음 포스팅에서 좀 더 디테일하게 살펴보도록 하겠습니다.
-
Positional Encoding : Transformer는 Recurrent model이나 Convolution model과 다소 다르기 때문에 Sequential data를 쓸 때 단어의 sequence 같은 정보를 따로 첨가해주어야 하는데, Positional Encoding (PE) 은 이러한 역할을 수행합니다. PE에서는 Sequential property를 나타내주기 위해 sine 과 cosine 함수 같은 주기성 있는 함수를 사용합니다. 구체적인 식은 아래와 같습니다.
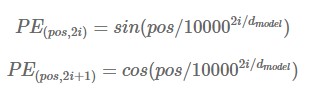
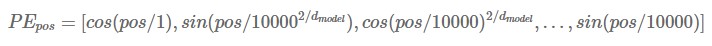
위에서 ‘pos’ 는 단어의 위치를 나타냅니다. 그것에 해당하는 PE vector는 k-th 요소가 다음과 같이 구성됩니다 : 1) k=2i+1 일 때는 cosine function 식 활용, 2) k=2i 일 때는 sine function 식 활용. 이렇게 해서 각 pos 에 대한 PE를 구하고 이것을 input or output embedding 값에 더해주게 되면 이들은 서로 다른 positional encoding value를 갖게 되어서 우리는 이제 position 별 구별을 하여 Sequential property를 적용할 수 있게 되는 것입니다. 참고로 식이 왜 저런 형식으로 나오는 지나 PE vector가 가지는 properties는 너무 테크니컬하여 일부 생략하였습니다.
이번 포스팅을 통해 Attention is all you need 라는 중요 논문의 전반적인 내용에 대해 살펴보았습니다. 핵심은 Attention과 Transformer가 Recurrent model을 그대로 차용한 것이 아님에도 불구하고 Sequential data를 빠르고 정확하게 처리할 수 있는 모델로 제시된다는 점입니다. 우리는 encoder와 decoder에 대한 Attention을 활용함으로써 Query와 가장 밀접한 연관성을 가진 값을 강조할 수 있으며, Parallelization 도 가능해졌다는 것을 기억해야 합니다. 테크니컬한 부분은 최대한 빼고 직관적인 개념을 이해할 수 있는 방향으로 포스팅을 작성했으니, Attention 에 대해 입문하시는 데 도움이 되셨기를 바랍니다 !