[NLP] RNN / LSTM details
RNN / LSTM details
이번 포스팅에서는 이전에 언급했던 RNN & LSTM 모델의 보다 구체적인 detail을 좀 더 논의해보도록 하겠습니다. 두 모델의 수식적인 부분과 application 등에 대해 알아봅시다.
RNN architecture
RNN 의 구체적인 구조는 아래와 같습니다.


위 그림들을 보면 RNN은 결국 New state(h_t)를 도출하기 위해 그 이전 Old state(h_t-1)와 해당 time step(t)에서의 input vector(x_t) 을 모두 사용함을 알 수 있습니다. 그래서 Recurrent 라는 이름이 붙게 된 것이죠. 이 두 요소에 W_hh, W_xh라는 trainable weights가 붙어 optimization에 사용되고, Activation function으로는 non-linear function인 tanh 가 활용됩니다. 결국 이렇게 형성된 RNN을 활용하게 되면 단순히 input vector에 대응하는 output이 산출되는 것이 아니라, input vector와 이전 output을 모두 고려한 output이 나오기 때문에 time dependent 특징을 가진 데이터가 잘 분석될 수 있습니다.
그렇다면 RNN은 어떤 식으로 현실에 적용될 수 있을까요?

위를 보면 알 수 있듯 Input과 Output이 single인지 multiple인지 등에 따라 다양한 application이 존재할 수 있습니다.
- One to many : Image captioning
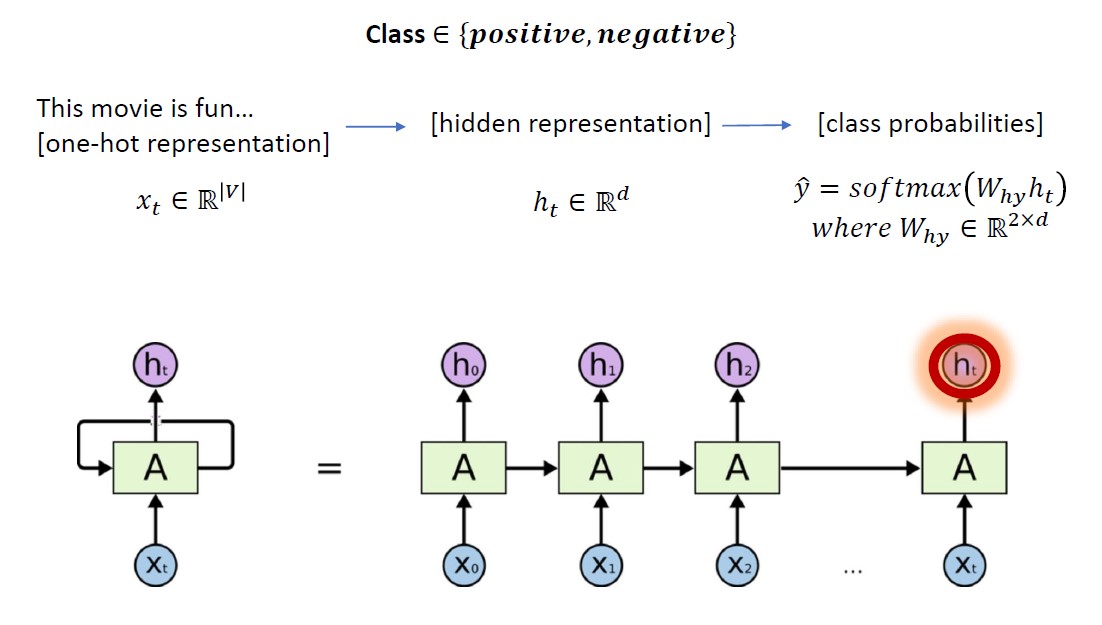
- Many to one : Sentiment analysis
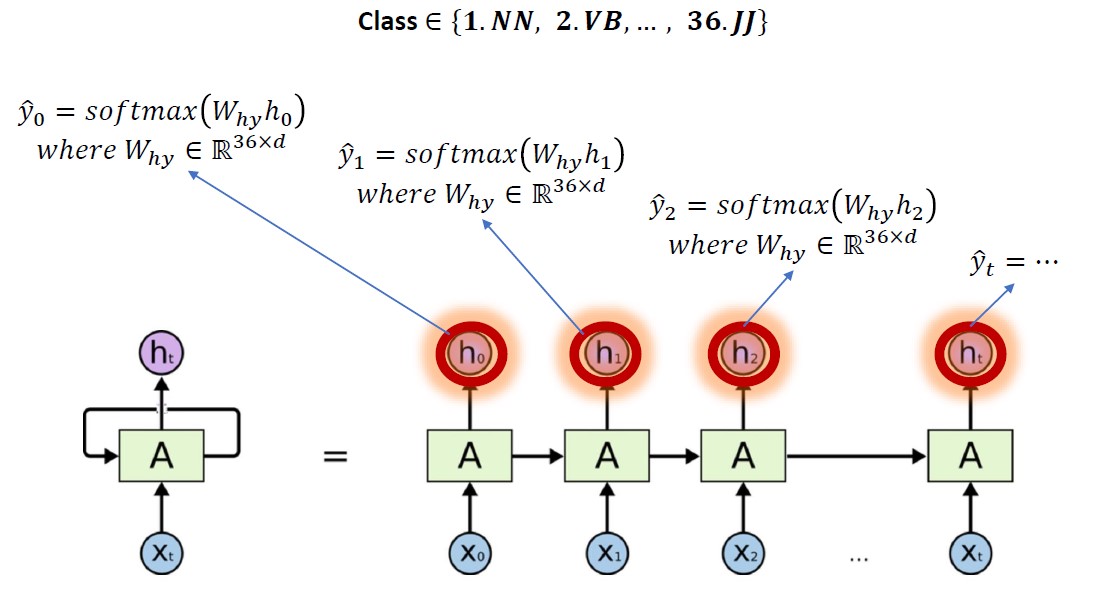
- Many to many : Machine Translation / POS tagging
그 중 Sentiment analysis와 POS tagging 구조를 그림으로 나타내면 아래와 같습니다.
LSTM architecture
LSTM은 RNN의 Long term dependency 문제를 완화하기 위해 고안된 모델로, 구체적인 내부구조는 다음과 같습니다.

그럼 이제 이 구조를 뜯어서 살펴봅시다.
1. Cell state :

Cell state는 LSTM 구조 전체를 관통하는 state로, 과정 내내 약간의 선형 interaction만 가지게 됩니다. 그래서 modeling 의 flow를 잘 간직하고 있는 state라고 보시면 되겠습니다. LSTM에서는 gates를 통해 Cell state에서 일부 정보를 지우거나 더하여 모델을 정교화 해나갑니다.
2. Forget gate :

Forget gate에서는 말그대로 Cell state에서 어떤 정보를 버릴 것인지 를 결정합니다. W_f, b_f 파라미터를 통해 그 정도를 조절합니다.
3. Input gate :

Input gate에서는 Forget gate와 반대로 Cell state에서 어떤 정보를 간직할지 를 결정합니다. 마찬가지로 W_i, b_i, W_c, b_c 파라미터를 통해 그 정도를 조절하고, tanh function을 activation function으로 활용합니다.
4. Output :


마지막으로 최종 Output을 내는 과정을 한번 더 통과하고 나면 LSTM의 결과물이 얻어지게 됩니다. 확실히 RNN 보다 gate 정교성 등을 강화하여 time dependent 한 정보를 더 오래 가져갈 수 있음을 짐작할 수 있습니다.
이번 포스팅을 통해 RNN & LSTM에 대한 보다 자세한 사항들을 살펴보았습니다. 도움이 되셨으면 좋겠네요!