[NLP] Word2Vec
Basic of NLP - Word representation
NLP를 자세히 공부하기 위해서는 우선 ‘단어’ 라는 것을 어떻게 표현하여 Neural Network 등의 모델에 넣어 여러 관련 task를 수행할 것인지부터 알아보아야 합니다. 단어를 numeric하게 나타내는 다양한 방법이 존재하지만, 이번 포스팅에서는 Bag of Words, TF-IDF, Word2Vec (CBoW, Skip gram) 같은 Basic methodology 위주로 살펴보도록 하겠습니다. 여기서 다뤄진 방법 외 좀 더 advanced된 기법들은 다음 포스팅에서 알아봅시다.
1) Bag of Words (BoW)
BoW 는 이름에서 파악할 수 있듯 주어진 텍스트에서 각 단어가 ‘몇 번’ 나오는 지, 즉 frequency를 통해 단어를 표현하는 방법입니다. 어려운 개념은 아니지만 더 이해하기 쉽도록 예를 들어보겠습니다.
Ex) 너는 영화를 보는 것 보다 책 읽는 것이 더 좋은 것 같다.
위와 같은 예시 문장이 있다고 합시다. 그렇다면 이것을 BoW 방식으로 표현하면 아래와 같이 됩니다.
Word dictionary : {‘너’: 0, ‘는’: 1, ‘영화’: 2, ‘를’: 3, ‘보는’: 4, ‘것’: 5, ‘보다’: 6, ‘책’: 7, ‘읽는’: 8, ‘이’: 9, ‘더’: 10, ‘좋은’: 11, ‘같다’: 12}
BoW result : [1,1,1,1,1,3,1,1,1,1,1,1,1]
위에서는 ‘것’ 이라는 단어가 3번 쓰였기 때문에 그것에 해당하는 BoW 값이 3임을 알 수 있습니다. 이렇게 Count based 방식을 쓰는 BoW는 간편하지만 단어의 순서를 고려하지 않는다는 점에서 한계점이 있습니다. 즉, 단어를 numeric 하게 표현하는 것은 가능하나 문맥 등이 고려되지 않아 단어의 ‘의미’를 담아내기에는 한계가 있다는 것입니다. 이러한 단점을 보완하기 위해 여러 다른 방법들이 고안되었는데, 이것은 차차 알아보도록 합시다.
2) TF-IDF
TF-IDF 는 BoW와 같은 Count based method 입니다. 이것은 Term Frequency - Inverse Document Frequency의 약자로, 말 그대로 단어의 빈도와 역 문서 빈도를 사용하여 단어를 표현합니다. 일단 TF와 IDF에 대해 좀 더 살펴봅시다.
-
TF : Term Frequency란 어떤 문서 d가 주어졌을 때 특정 단어 w가 등장한 횟수를 지칭하는 말로, ‘나는 사과를 먹었다’ 는 예시에서 각 단어는 모두 한 번씩만 등장했기 때문에 이들의 TF 값은 1 이라고 볼 수 있습니다.
-
DF : Document Frequency란 특정 단어 w가 등장한 문서의 개수를 지칭하는 것입니다. 만약 ‘나’ 라는 단어가 등장한 문서가 총 10개 라면, 이 단어의 DF 값은 10이 됩니다.
-
IDF : Inverse Document Frequency란 DF에 반비례하는 수로, 구체적인 식은 아래와 같습니다.
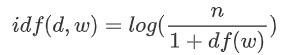
그냥 역수를 취하지 않고 위처럼 복잡한 형태를 취하는 이유는, 텍스트 데이터가 방대해지며 n이 커짐에 따라 IDF 값이 급증하지 않도록 log를 붙이고 분모가 0이 되는 것을 방지하기 위해 1을 더해준 것입니다.
TF-IDF의 최종값은 문서별로 각 단어가 얼마나 등장했는지 나타내는 TF 값에 IDF 값을 곱해서 나오게 됩니다. 직관적으로 살펴보자면, 해당 문서에서 어떤 단어가 많이 등장하면 그것의 가중치를 높게 주고 단어가 문서를 통틀어 이 문서 저 문서 모두에 많이 나왔다면 그 단어가 문서 내에서 지니는 고유한 중요도가 감퇴한다고 보아 그 값에 반비례하는 가중치를 반영해준다, 정도로 보시면 되겠습니다. 이 방법 또한 BoW 처럼 계산이 복잡하지는 않으나, 역시나 순서를 고려하지 않는 등의 문제가 남아있습니다.
Word2Vec
사실 정말 간단하게 생각하면 각 단어를 모두 원핫벡터로 표현하는 것도 가능합니다. 하지만 그렇게 되면 NLP task 에서 중요하게 다뤄지는 단어 간 유사도 등을 측정하기 힘들고, 데이터도 너무 sparse 해지기 때문에 분석 시 여러 어려움이 수반됩니다. 따라서 연구자들은 Distributional hypothesis 가정 하 단어를 표현하는 Distributed Representation 방법을 고안해냅니다. 여기서 Distributional hypothesis 란 어떤 단어들이 비슷한 단어와 함께 비슷한 위치에서 나타나면 그 의미가 서로 비슷할 것이다 라는 가정이며, 이를 통해 단어의 ‘의미’를 어느 정도 반영할 수 있게 됩니다. Word2Vec 은 이렇게 단어의 의미를 다차원에 분산하여 표현하고자 하는 Word Embedding 방식 중 하나이며, CBoW와 Skip-gram이라는 두가지 방법이 존재합니다.
3) CBoW (Continuous Bag of Words)
CBoW는 주변부 단어들을 활용하여 타겟 단어를 예측하는 방법입니다. 이해하기 쉽게 예를 들어봅시다.
Ex) ‘나는 사과나 오렌지 같은 과일을 엄청 좋아한다.’
위와 같은 예문이 있을 때, CBoW는 ‘과일’ 이라는 단어를 앞뒤에 등장한 다른 단어들을 통해 유추하고자 하는 것입니다. 물론 앞뒤 단어를 모두 보는 것은 아니고, window를 결정하여 그 범위에 해당하는 단어를 중심으로 살펴봅니다. 만약 window를 2로 준다면 ‘과일’ 을 예측하기 위해 {‘오렌지’, ‘같은’, ‘을’, ‘엄청’} 을 주변 단어로 취급하는 것이죠. CBoW에서는 문장의 각 단어를 골고루 학습하기 위해 타겟 단어를 움직여가면서 분석을 진행합니다 (sliding window). 예시 문장은 다르지만 CBoW를 간단히 도식화 하면 아래와 같습니다.

그렇다면 좀 더 구체적으로, 어떻게 주변 단어로부터 타겟 단어를 예측하는 걸까요? CBoW에서는 주로 한 개의 hidden layer를 사용하여 주변 단어에 해당하는 원핫벡터에 가중치 매트릭스 W를 곱해 타겟 단어를 예측한 뒤, backpropagation을 통해 가중치를 업데이트 해가며 학습을 진행합니다. 그림으로 살펴보면 아래와 같습니다.

Loss :

(Input -> hidden) & (hidden -> Output) 부분에 해당하는 가중치 매트릭스의 차원을 잘 맞춰주는 것에 유의합시다. 이 과정이 완료되면 W의 row나 W’의 column 중 어떤 것을 단어의 임베딩 벡터로 사용할지, 평균 등을 취할 것인지를 판단만 해주면 됩니다.
4) Skip-gram
위에서 CBoW를 이해했다면 Skip-gram은 쉽습니다. CBoW와 로직은 비슷하지만 일종의 방향이 반대인 방법이라고 보시면 될 것 같습니다. 즉, Skip-gram은 타겟 단어를 통해 주변 단어들을 유추해내는 방식입니다. CBoW와 비교하여 주변 단어와 타겟 단어 간 예측 방향이 달라진다고 보시면 됩니다. 예측하는 방법 또한 CBoW와 유사합니다. Input 과 Output 만 달라질 뿐, 비슷하게 W & W’ 가중치 매트릭스를 주고 loss를 이용하여 backpropagation을 진행해주면 됩니다. 도식화 하면 아래와 같습니다.

참고로 Word2Vec을 사용한 실제 응용사례들을 살펴보면 CBoW 보단 Skip-gram이 더 많습니다. 일반적으로 Skip-gram의 성능이 더 낫다고 합니다.
자, 이렇게 해서 지금까지 단어를 표현하는 4가지 방법에 대해 살펴보았습니다. 지금부터는 텍스트 분야는 아니지만 NLP 분야에서 고안된 Bag of Words 방식이 CV 분야 task인 Image retrieval 에 어떻게 응용되었는지 간단하게 알아보도록 하겠습니다.
Image retrieval & BoW
일단 Image retrieval 은 한국말로 ‘정보 검색’ 이라고 표현되기도 하는데, 어떤 이미지가 주어졌을 때 그것과 유사한 이미지를 검색해주는 것을 포괄합니다. 여기에 BoW 가 활용되는 방법은 다양합니다만, 일반적인 흐름은 이러합니다 : 이미지를 여러 부분으로 나눠서 feature를 뽑아낸 뒤 그러한 micro features의 codebook (codewords dictionary) 을 생성합니다. 이러한 것은 Bag of Features (BoF) 라고 부르기도 하며, 이 때 feature 가 일종의 visual ‘word’ 가 되는 것으로 이해하시면 되겠습니다. 이렇게 해서 이미지 인식 후 codebook과 연동하여 visual word 별 히스토그램을 구하면 빈도수가 높은 codebook 내 class가 인식된 category가 되는 것이고, 이 방식을 여러 이미지들에 적용하고 적당한 metric을 써서 유사도를 측정하면 최종적으로 Image retrieval task 를 수행할 수 있게 됩니다.
물론 이미지에 BoW를 적용하면 위치 정보가 사라지고 이미지의 구간을 어떻게 나눌지 등이 명확하지 않다는 점에서 단점이 존재하기는 합니다. 이러한 단점들을 보완하기 위해 여러 논문들이 나왔지만 이번 포스팅은 CV가 메인이 아니기 때문에 Image retrieval 분야에서 텍스트 기법인 BoW가 어떻게 활용될 수 있는지만 간단히 소개하고 넘어가도록 하겠습니다.
이번 포스팅을 통해 NLP 분야에서의 단어 표현 방식 몇 가지와 CV 분야에서의 응용을 간략하게 살펴보았습니다. 다음 포스팅에서는 좀 더 advanced 된 표현 방식들과 기타 응용 사례 혹은 실습 코드 등을 다뤄보도록 하겠습니다.