[NLP] Seq2Seq
Seq2Seq
Seq2Seq는 용어 그대로 sequence가 input으로 들어가서 모델을 거친 후 sequence가 반환되는 것을 지칭하는 것으로, NLP에서는 주로 Neural Machine Translation (NMT) 분야에 많이 활용되고 있다. 일단 sequential data가 input으로 들어가서 sequential data가 다시 output으로 나온다는 것에서 우리는 DNN처럼 단순히 layer를 쌓아 모델링하는 것보다 더 정교하게 sequential property를 반영해줄 수 있는 모델이 필요함을 알 수 있다. 이러한 쟁점을 나름 잘 해결해준 RNN이 등장하며 Seq2Seq 모델은 더욱 뜨거운 관심을 받게 되었고, 그 결과 지금까지도 여러 분야에서 사용되고 있다.
1. Architecture
Seq2Seq 모델은 주로 Encoder + Decoder의 구조로 이루어져 있으며, 각 부분에서는 RNN과 같은 recurrent model이 쓰인다. 그림으로 표현하면 아래와 같은데, 이 때 Encoder는 input을 받아 그것이 가진 정보값을 압축하여 context vector를 만드는 역할을 하고, Decoder는 앞서 만들어진 Encoder 값을 받아 output을 내놓는 역할을 한다.

보통 모델 설명을 할 때에는 Encoder나 Decoder에 RNN이 쓰인다고 표현하고 실제로 그런 경우도 있지만, vanilla RNN이 가진 여러 문제들 때문에 practical하게는 LSTM을 주로 사용한다고 한다. RNN의 문제점 같은 경우는 RNN 포스팅을 따로 참조하도록 하자.
2. Training
사실 이러한 구조의 Seq2Seq 모델은 훈련과정과 예측과정 간 차이가 존재한다. 이 차이의 대표적인 예가 바로 Teacher forcing 이다. 그렇다면 Teacher forcing이란 무엇인지 좀 더 자세히 살펴보자.
-
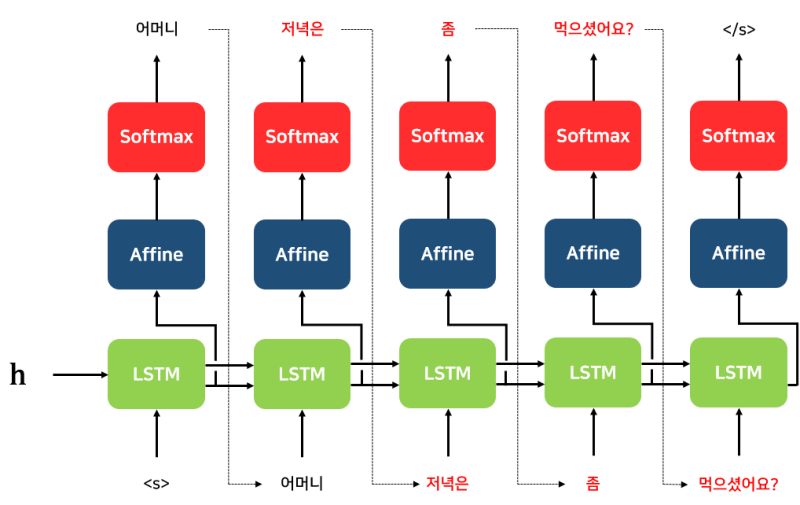
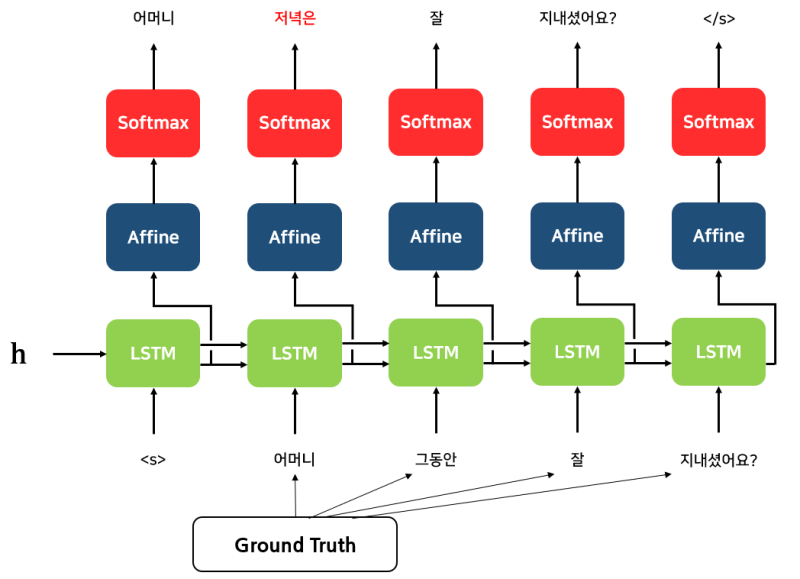
Teacher forcing : Teacher forcing이란 정답인 output을 낼 수 있도록 디코더의 입력값으로 Ground Truth 값을 넣어주는 것을 의미한다. 위 그림을 예시로 들면, _je suis etudiant_를 잘 산출해낼 수 있도록 아예 디코더에 실제 정답을 입력해주는 것이다. 여기서 눈치챌 수 있듯, 이러한 Teacher forcing은 예측과정이 아닌 훈련과정에서 사용된다. Teacher forcing이 쓰이지 않게 되면 잘못된 예측이 계속해서 다음 디코더로 이어지게 되고, 그러면 셀을 거쳐갈수록 정확도가 떨어지게 된다. 따라서 Training을 시킬 때 디코더가 답을 잘 예측할 수 있도록 강요 아닌 강요를 하여 모델의 성능/효율성을 높이고자 하는 것이다. 물론 Teacher forcing을 쓰게 되면 inference 과정에서 Ground Truth를 입력해줄 수 없어 이전 출력값을 기반으로 계속 예측을 해나가야 한다는 단점 (‘Exposure bias problem‘)이 존재하기는 하지만 일부 연구에서는 이러한 단점이 큰 영향을 미치지는 않는다는 사실이 밝혀지기도 했다. 사실 recurrent 모델처럼 Backpropagation through time (BPTT)을 통해 계속해서 오류를 역전파 해나가는 기법도 어느정도 디코더의 정확도를 높여준다고 할 수 있지만, Teacher forcing을 쓰면 목적 달성에 더욱 다가갈 수 있게 된다. BPTT는 RNN 포스팅에서 더 자세히 다뤄보도록 하자. 참고로, Teacher forcing을 썼을 때와 그렇지 않았을 때를 도식화하여 비교해보면 아래와 같다.
-> Teacher forcing (X) :
-> Teacher forcing (O) :
Teacher forcing이 쓰이지 않는 예측과정을 정리해보면 다음과 같다.
- 1) 인코더 셀 각 시점에 sequential 입력값들이 들어오고, 인코더는 이 input들을 context vector로 압축시켜 Decoder에 넘겨준다.
- 2) 첫번째 디코더 셀은 이러한 context vector를 받아 output을 낸다.
- 3) 그 다음 시점 셀부터는 이전 디코더 셀이 예측한 output 또한 입력으로 받아 또 다음 output을 예측한다. (일종의 conditional probability 활용)
- 4) 이러한 과정을 거쳐 입력된 sequential data가 또 다른 sequential data으로 산출되게 된다.
Seq2Seq의 훈련과정은 위의 예측과정과 유사하지만 Teacher forcing이 첨가되었다고 보면 이해하기 쉬울 것이다.
부가적으로, Training 과정에서 큰 흐름 외 디테일적인 측면에서의 특징 몇가지를 꼽아본다면 다음을 들 수 있다.
-
-
디코더를 거친후 Dense+Softmax를 활용하여 output sequence의 각 요소별 확률값을 산출하고, 그것을 바탕으로 최종 ouput 값이 결정된다.

-
인코더에 input 넣어줄 때 입력순서를 거꾸로 하기
Ex) ‘I am student’ 가 아닌 ‘student am I’ 처럼 넣어주어야 디코더의 첫부분이 ‘I’의 영향을 좀 더 받아서 ‘je’ 라는 올바른 번역값을 내놓을 가능성이 높아진다.
-
아예 디코더의 첫 단어 자체가 잘못 출력된다면? 그럼 다음 셀의 정확도도 같이 낮아지게 된다. 이를 방지하기 위한 방법으로 Teacher forcing 외 Top-k Beam Search를 활용한다.
-> Beam search decoder 란 사용자가 사전에 정한 k를 바탕으로 디코더의 각 스텝에서 가장 나올 가능성이 높은 k개의 후보를 고려하여 디코딩을 하는 것으로, k=2 인 경우를 그림으로 표현하자면 아래와 같다.

Greedy Search 처럼 각 스텝에서 확률이 가장 높은 1개만을 선택하여 넘겨주면 탐색 시간은 줄일 수 있겠지만 한번 잘못 끼워진 단추가 그 다음에도 안좋은 영향을 끼쳐 악순환이 지속될 수 있어 output이 최적점과 멀어질 수 있다. 따라서 Beam Search를 통해 안전성을 부여하는 것이 좋다. 하지만 이 방법 역시 장점이 있는 대신 k의 크기에 따라 디코딩 시간이 크게 늘어날 수 있다는 단점이 존재하므로, 정확도와 속도 간 trade-off를 고려하여 신중히 방법론 및 파라미터를 결정해주어야 한다.
-
3. Problems ?
Seq2Seq 모델이 NMT 등의 분야에서 많은 성과를 거뒀음은 분명하나, 그렇다고 완벽한 모델인 것은 아니다. Encoder가 과연 입력값의 모든 정보를 잘 보존하고 있는지에 대한 의문 (Long-term dependency problem 등 고려 필요)과 Decoder가 모두 같은 인코더 결과값 (context vector)을 기반으로 하고 있다는 점 등 문제점이 존재한다.
따라서 이러한 문제점들을 완화하기 위해 이후에 나온 Attention이 Seq2Seq이 많이 쓰이던 NMT 분야 등에서 사용되기 시작하였는데, Attention에 대해서는 다른 포스팅에서 좀 더 자세히 다뤄보도록 하자.